Machine Learning on Silicon Labs Devices from Scratch#
This guide assumes familiarity with the content of the Getting Started Guide. It provides details of working with the TensorFlow API, as an alternative to the automatic initialization provided by Silicon Labs as described in the guide on Adding Machine Learning to a New Project.
Model Inclusion#
With the TensorFlow Lite Micro component added in the Project Configurator, the next step is to load the model file into the project. To do this, copy the .tflite model file into the config/tflite directory of the project. The project configurator provides a tool that will automatically convert .tflite files into a sl_tflite_micro_model source and header files. The full documentation for this tool is available at Flatbuffer Converter Tool.
To do this step manually, a C array can be created from the .tflite using a tool such as xxd.
TFLM Initialization and Inference#
To instantiate and use the TensorFlow APIs, follow the steps below to add TFLM functionality to the application layer of a project. This guide closely follows the TFLM Getting Started Guide, and is adapted for use with Silicon Labs' projects.
A special note needs to be taken regarding the operations used by TensorFlow. Operations are specific types of computations executed by a layer in the neural network. All operations may be included in a project at once, but doing this may increase the binary size dramatically (>100kB). The more efficient option is to only include the operations necessary to run a specific model. Both options are described in the steps below.
0. Disable the automatic initialization provided by the TensorFlow Lite Micro component#
To manually set up TensorFlow, first disable automatic initialization of the model by disabling "Automatically initialize model" in the configuration header for the TensorFlow Lite Micro component (sl_tflite_micro_config.h).


1. Include the library headers#
If using a custom, limited set of operations (recommended):
#include "tensorflow/lite/micro/micro_mutable_op_resolver.h"
#include "tensorflow/lite/micro/tflite_bridge/micro_error_reporter.h"
#include "tensorflow/lite/micro/micro_interpreter.h"
#include "tensorflow/lite/schema/schema_generated.h"
#include "tensorflow/lite/version.h"If using all operations:
#include "tensorflow/lite/micro/all_ops_resolver.h"
#include "tensorflow/lite/micro/micro_error_reporter.h"
#include "tensorflow/lite/micro/micro_interpreter.h"
#include "tensorflow/lite/schema/schema_generated.h"
#include "tensorflow/lite/version.h"2. Include the model header#
Because the autogen/ folder is always included in the project include paths, an imported model may be generically included in any project source file with:
#include "sl_tflite_micro_model.h"If not using the Flatbuffer Converter Tool, include the file containing your model definition instead.
3. Define a Memory Arena#
TensorFlow requires a memory arena for runtime storage of input, output, and intermediate arrays. This arena should be statically allocated, and the size of the arena depends on the model used. It is recommended to start with a large arena size during prototyping.
constexpr int tensor_arena_size = 10 * 1024;
uint8_t tensor_arena[tensor_arena_size];Note: After prototyping, it is recommended to manually tune the memory arena size to the model used. After the model is finalized, start with a large arena size and incrementally decrease it until interpreter allocation (described below) fails.
4. Set up Logging#
This should be performed even if the Debug Logging Disabled component is used. It is recommended to instantiate this statically and call the logger init functions during the app_init() sequence in app.cpp
static tflite::MicroErrorReporter micro_error_reporter;
tflite::ErrorReporter* error_reporter = &micro_error_reporter;5. Load the Model#
Continuing during the app_init() sequence, the next step is to load the model into tflite:
const tflite::Model* model = ::tflite::GetModel(sl_tflite_model_array);
if (model->version() != TFLITE_SCHEMA_VERSION) {
TF_LITE_REPORT_ERROR(error_reporter,
"Model provided is schema version %d not equal "
"to supported version %d.\n",
model->version(), TFLITE_SCHEMA_VERSION);
}6. Instantiate the Operations Resolver#
If using all operations, this is very straightforward. During app_init(), statically instantiate the resolver via:
static tflite::AllOpsResolver resolver;Note: loading all operations will result in large increases to the binary size. It is recommended to use a custom set of operations.
If using a custom set of operations, a mutable ops resolver must be configured and initialized. This will vary based on the model and application. To determine the operations utilized in a given .tflite file, third party tools such as netron may be used to visualize the network and inspect which operations are in use.
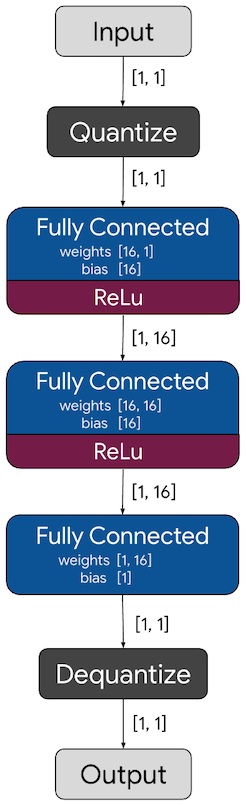
The example below loads the minimal operators required for the TensorFlow hello_world example model. As shown in the Netron visualization, this only requires fully connected layers:
#define NUM_OPS 1
static tflite::MicroMutableOpResolver<NUM_OPS> micro_op_resolver;
if (micro_op_resolver.AddFullyConnected() != kTfLiteOk) {
return;
}If using the Flatbuffer Converter Tool, it generates a C preprocessor macro that automatically sets up the optimal tflite::MicroMutableOpResolver for the a flatbuffer:
#include "sl_tflite_micro_opcode_resolver.h"
SL_TFLITE_MICRO_OPCODE_RESOLVER(micro_op_resolver, error_reporter);7. Initialize the Interpreter#
The final step during app_init() is to instantiate an interpreter and allocate buffers within the memory arena for the interpreter to use:
// static declaration
tflite::MicroInterpreter* interpreter = nullptr;
// initialization in app_init
tflite::MicroInterpreter interpreter(model, micro_op_resolver, tensor_arena,
tensor_arena_size, error_reporter);
interpreter = &interpreter_struct;
TfLiteStatus allocate_status = interpreter.AllocateTensors();
if (allocate_status != kTfLiteOk) {
TF_LITE_REPORT_ERROR(error_reporter, "AllocateTensors() failed");
return;
}The allocation will fail if the arena is too small to fit all the operations and buffers required by the model. Adjust the tensor_arena_size accordingly to resolve the issue.
8. Run the Model#
For default behavior in bare metal application, it is recommended to run the model during app_process_action() in app.cpp in order for periodic inferences to occur during the standard event loop. Running the model involves three stages:
Sensor data is pre-processed (if necessary) and then is provided as input to the interpreter.
TfLiteTensor* input = interpreter.input(0); // stores 0.0 to the input tensor of the model input->data.f[0] = 0.;It is important to match the shape of the incoming sensor data to the shape expected by the model. This can optionally be queried by checking properties defined in the
inputstruct. An example of this for the hello_world example is shown below:TfLiteTensor* input = interpreter->input(0); if ((input->dims->size != 1) || (input->type != kTfLiteFloat32)) { TF_LITE_REPORT_ERROR(error_reporter, "Bad input tensor parameters in model"); return; }The interpreter is then invoked to run all layers of the model.
TfLiteStatus invoke_status = interpreter->Invoke(); if (invoke_status != kTfLiteOk) { TF_LITE_REPORT_ERROR(error_reporter, "Invoke failed on x_val: %f\n", static_cast<double>(x_val)); return; }The output prediction is read from the interpreter.
TfLiteTensor* output = interpreter->output(0);
// Obtain the output value from the tensor
float value = output->data.f[0];At this point, application-dependent behavior based on the output prediction should be performed. The application will run inference on each iteration of app_process_action().
Full Code Snippet#
After following the steps above and choosing to use the mutable ops resolver, the resulting app.cpp now appears as follows:
#include "tensorflow/lite/micro/micro_mutable_op_resolver.h"
#include "tensorflow/lite/micro/micro_error_reporter.h"
#include "tensorflow/lite/micro/micro_interpreter.h"
#include "tensorflow/lite/schema/schema_generated.h"
#include "tensorflow/lite/version.h"
#include "sl_tflite_micro_model.h"
#define NUM_OPS 1
constexpr int tensor_arena_size = 10 * 1024;
uint8_t tensor_arena[tensor_arena_size];
tflite::MicroInterpreter* interpreter = nullptr;
/***************************************************************************//**
* Initialize application.
******************************************************************************/
void app_init(void)
{
static tflite::MicroErrorReporter micro_error_reporter;
tflite::ErrorReporter* error_reporter = µ_error_reporter;
const tflite::Model* model = ::tflite::GetModel(g_model);
if (model->version() != TFLITE_SCHEMA_VERSION) {
TF_LITE_REPORT_ERROR(error_reporter,
"Model provided is schema version %d not equal "
"to supported version %d.\n",
model->version(), TFLITE_SCHEMA_VERSION);
}
static tflite::MicroMutableOpResolver<NUM_OPS> micro_op_resolver;
if (micro_op_resolver.AddFullyConnected() != kTfLiteOk) {
return;
}
static tflite::MicroInterpreter interpreter_struct(model, micro_op_resolver, tensor_arena,
tensor_arena_size, error_reporter);
interpreter = &interpreter_struct;
TfLiteStatus allocate_status = interpreter.AllocateTensors();
if (allocate_status != kTfLiteOk) {
TF_LITE_REPORT_ERROR(error_reporter, "AllocateTensors() failed");
return;
}
}
/***************************************************************************//**
* App ticking function.
******************************************************************************/
void app_process_action(void)
{
// stores 0.0 to the input tensor of the model
TfLiteTensor* input = interpreter->input(0);
input->data.f[0] = 0.;
TfLiteStatus invoke_status = interpreter->Invoke();
if (invoke_status != kTfLiteOk) {
TF_LITE_REPORT_ERROR(error_reporter, "Invoke failed on x_val: %f\n",
static_cast<double>(x_val));
return;
}
TfLiteTensor* output = interpreter->output(0);
float value = output->data.f[0];
}Examples#
As described in the Sample Application Overview, examples developed by the TensorFlow team demonstrating the hello_world example described in this guide, as well as a simple speech recognition example micro_speech, are included in the Gecko SDK.
Note that the micro_speech example demonstrates use of the MicroMutableOpResolver to only load required operations.