Developing with Silicon Labs Machine Learning (AI/ML)#
Machine learning is a subset of artificial intelligence (AI) that enables systems to learn from data and improve their performance without being explicitly programmed. It involves algorithms that identify patterns and make decisions based on input data. Deep learning, a specialized branch of machine learning, uses neural networks with many layers to model complex patterns and achieve high accuracy in tasks like image and speech recognition. Together, these technologies power many modern applications, from recommendation systems to autonomous vehicles. As part of the broader AI field, machine learning and deep learning are key to creating systems that can adapt, reason, and act intelligently.
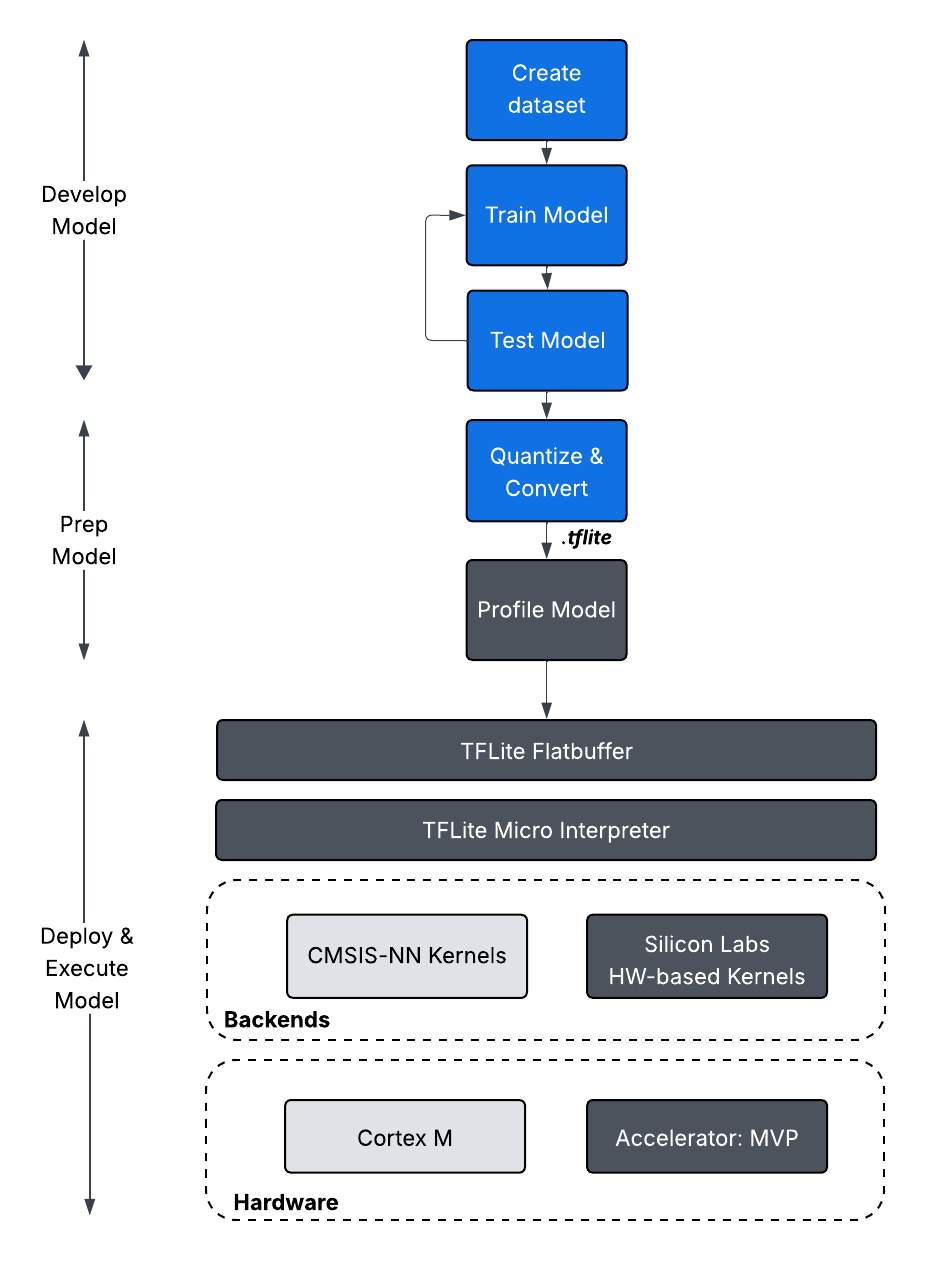
Silicon Labs currently supports TensorFlow Lite for Microcontrollers (TFLM) and associated software as an extension to SiSDK.
The content on these pages is intended for those who want to experiment with or are already developing a Machine Learning application using Silicon Labs technology.
For Silicon Labs Machine Learning product information: See the product pages on silabs.com.
For background on Machine Learning: The Fundamentals section is a good place to start.
To get started with development: See the Getting Started section to get started working with example applications.
If you are already in development: See the Developer's Guide.
If you are using the Machine Learning SDK version 1.3.x or earlier: See the AI/ML Extension Setup guide to transition from v1.x to v2.x of the AI/ML SDK. The earlier versions were supported as a software component of SiSDK, the stack has been moved into an extension now.
For Silicon Labs AI/ML Extension Source Code: See the AI/ML Extension link to GitHub.