Zigbee Routing Concepts#
Overview#
Zigbee has several routing mechanisms that can be used based on the network and expected traffic patterns. In Zigbee Specification, document 05-3474, section 3.4 describes the frame format for command frames, and section 3.6.3 describes routing behavior.
The application designer should choose which mechanism to use as part of the system architecture and design. In actual practice one application may use several of these routing mechanisms, because some devices may be performing one-to-one communications while other devices may be communicating to a central monitoring device. The types of routing discussed below are:
Table Routing
Broadcast Routing
Multicast Routing
Many-to-One/Source Routing
Table Routing#
Routes are formed when one node sends a route request to discover the path to another node. After a route is discovered between the two nodes, the source node sends its message to the first node in the route, as specified in the source node's routing table. Each intermediate node uses its own routing table to forward the message to the next node (that is "hop") along the route until the message reaches its destination. If a route fails, a route error is sent back to the originator of the message who can then rediscover the route.
Broadcast Routing#
Broadcast routing is a mechanism to send a message to all devices in a network. Network-level broadcast options exist to send to routers only, to all non-sleeping nodes including end devices, or also to send to sleeping end devices. A broadcast message is repeated by all router-capable devices in the network three times to ensure delivery to all devices. While a broadcast is a reliable means of sending a message, it should be used sparingly because of the impact on network performance. Repeated broadcasts can limit any other traffic that may be occurring in the network. Broadcasts are also not a reliable means of delivery to a sleeping device because the parent device is responsible for buffering the message for the sleeping child but may drop the message before the end device wakes to receive it.
Multicast Routing#
Multicast routing provides a one-to-many routing option. A multicast is used when one device wants to send a message to a group of devices, such as a light switch sending an on command to a bank of 10 lights. Under this mechanism, all the devices are joined into a multicast group. Only those devices that are members of the group will receive messages, although other devices will route these multicast messages. A multicast is a filtered limited broadcast. It should be used only as necessary in applications, because over-use of broadcast mechanisms can degrade network performance. A multicast message is never acknowledged.
Many-to-One/Source Routing#
Many-to-one routing is a simple mechanism to allow an entire network to have a path to a central control or monitoring device. Under normal table routing, the central device and the devices immediately surrounding it would need routing table space to store a next hop for each device in the network, as well as an entry to the central device itself. Given the memory limited devices often used in Zigbee networks, these large tables are undesirable.
Under many-to-one routing, the central device, known as a "concentrator," sends a single route discovery that established a single route table entry in all routers to provide the next hop to the central device. This yields a result similar to that of table routing, but with a single many-to-one route request rather than many individual, one-to-one route requests from each router towards the concentrator.
All devices in the network then have a next hop path to the concentrator and only a single table entry is used. However, often the central device also needs to send messages back out into the network. This would result in a more significant increase in route table size, particularly for those nodes closest to the concentrator, since they are relay points in the concentrator’s many outbound routes to the rest of the network. Instead, incoming messages to the concentrator first use a route record message to store the sequence of hops used along the route. The concentrator then stores these next hop routes in reverse order as "source routes" in a locally held table known as a "source route table". Outgoing messages include this source route in the network header of the message. The message is then routed using next hops from the network header instead of from the route table. This provides for large scalable networks without increasing the memory requirements of all devices. It should be noted that the concentrator requires some additional memory if it is storing these source routes.
For detailed information on message delivery, refer to the Zigbee specification available from https://csa-iot.org/.
Using Link Quality to Aid in Routing#
The information in this section is provided for those wishing to understand the details of the network layer's operation, which can prove useful during troubleshooting. Otherwise, link status messages are handled automatically by the stack and application writers need not be concerned with it.
Links in wireless networks often have asymmetrical link quality due to variations in the local noise floor, receiver sensitivity, and transmit power. The routing layer must use knowledge of the quality of links in both directions in order to establish working routes and to optimize the reliability and efficiency of those routes. It can also use the knowledge to establish reliable two-way routes with a single discovery.
Zigbee routers keep track of inbound link quality in the neighbor table, typically by averaging LQI (Link Quality Indicator) measurements made by the physical layer. To handle link asymmetry, the Zigbee PRO stack profile specifies that routers obtain and store costs of outgoing links as measured by their neighbors. This is accomplished by exchanging link status information through periodic one hop broadcasts, referred to as "link status" messages. The link status algorithm is explained below, as implemented in EmberZNet PRO.
Description of Relevant Neighbor Table Fields#
Zigbee routers store information about neighboring Zigbee devices in a neighbor table. For each router neighbor, the entry includes the following fields:
average incoming LQI
outgoing cost
age
The incoming LQI field is an exponentially weighted moving average of the LQI for all incoming packets from the neighbor. The incoming cost for the neighbor is computed from this value using a lookup table.
The outgoing cost is the incoming cost reported by the neighbor in its neighbor exchange messages. An outgoing cost of 0 means the cost is unknown. An entry is called "two-way" if it has a nonzero outgoing cost, and "one-way" otherwise.
The age field measures the amount of time since the last neighbor exchange message was received. A new entry starts at age 0. The age is incremented every EM_NEIGHBOR_AGING_PERIOD, currently 16 seconds. Receiving a neighbor exchange packet resets the age to EM_MIN_NEIGHBOR_AGE, as long as the age is already at least EM_MIN_NEIGHBOR_AGE (currently defined to be 3). This makes it possible to recognize nodes that have been recently added to the table and avoid evicting them, which reduces thrashing in a dense network. If the age is greater than EM_STALE_NEIGHBOR (currently 6), the entry is considered stale and the outgoing cost is reset to 0.
Link Status Messages#
Routers send link status messages every 16 seconds plus or minus 2 seconds of jitter. If the router has no two-way links it sends them eight times faster. The packet is sent as a one-hop broadcast with no retries. In the EmberZNet PRO stack, they are sent as Zigbee network command frames.
The payload contains a list of short IDs of all non-stale neighbors, along with their incoming and outgoing costs. The incoming cost is always a value between 1 and 7. The outgoing cost is a value between 0 and 7, with the value 0 indicating an unknown outgoing cost. For frame format details, refer to the Zigbee specification. Link status messages are also automatically decoded by the Simplicity Studio Network Analyzer for easy reference.
Upon receipt of a link status message, either a neighbor entry already exists for that neighbor, or one is added if there is space or if the neighbor selection policy decides to replace an old entry with it. If the entry does not get into the table, the packet is simply dropped. If it does get in, then the outgoing cost field is updated with the incoming cost to the receiving node as listed in the sender's neighbor exchange message. If the receiver is not listed in the message, the outgoing cost field is set to 0. The age field is set to EM_MIN_NEIGHBOR_AGE.
How Two-way Costs are Used by the Network Layer#
As mentioned above, the routing algorithm makes use of the bidirectional cost information to avoid creating broken routes, and to optimize the efficiency and robustness of established routes. For the reader familiar with the Zigbee route discovery process, this subsection gives details of how the outgoing cost is used. The mechanism is surprisingly simple, but provides all the benefits mentioned above.
Upon receipt of a route request command frame, the neighbor table is searched for an entry corresponding to the transmitting device. If no such entry is found, or if the outgoing cost field of the entry has a value of 0, the frame is discarded and route request processing is terminated.
If an entry is found with non-zero outgoing cost, the maximum of the incoming and outgoing costs is used for the purposes of the path cost calculation, instead of only the incoming cost. This value is also used to increment the path cost field of the route request frame prior to retransmission.
Key Concept: Rapid Response#
Rapid response allows a node that has been powered on or reset to rapidly acquire two-way links with its neighbors, minimizing the amount of time the application must wait for the stack to be ready to participate in routing. This feature is 100% Zigbee-compatible.
If a link status message is received that contains no two-way links, and the receiver has added the sender to its neighbor table, then the receiver sends its own link status message immediately in order to get the sender started quickly. The message is still jittered by 2 seconds to avoid collisions with other rapid responders. To avoid a chain reaction, rapid responders must themselves have at least one two-way link.
Key Concept: Connectivity Management#
By nature Zigbee devices are RAM-constrained, but often Zigbee networks are dense. This means that each router is within radio range of a large number of other routers. In such cases, the number of neighbors can exceed the maximum number of entries in a device's neighbor table. In such cases, the wrong choice of which neighbors to keep can lead to routing inefficiencies or worse — a disconnected network. The EmberZNet PRO stack employs 100% Zigbee-compatible algorithms to manage the selection of neighbors in dense networks to optimize network connectivity.
Route Discovery & Repair#
Routing in Zigbee is automatically handled by the networking layer, and the application developer usually does not need to be concerned with its behavior. However, it is useful to have a feel for how the network behaves when a route needs to be discovered or repaired.
Route Discovery#
Route discovery is initiated when a unicast message is sent from one device to another and there is no pre-existing route.
We assume that there is no existing route so the networking software will begin the process of route discovery. For simplicity, assume that the routing tables of all devices are blank.
For example, assume that device A needs to send a message to device C, as shown in the following figure. Device A will broadcast a message to the entire network asking the device C to reply. This broadcast message also serves to establish a temporary route back to A, as each intermediate device records the device from which it received the message. Routes are updated on intermediate nodes — note that these are temporary entries that have a shorter lifetime than regular entries and are not intended for re-use. Because A is a one-hop neighbor, B and D do not need to store routing information about it.
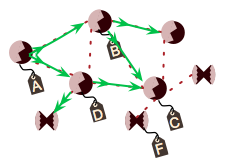
C could use either B or D as its next hop back to A. Zigbee leaves this choice to the implementation; Silicon Labs uses a weighting algorithm to choose the most apparently reliable next hop.
When the message reaches device C, C sends a special unicast message (called a Route Response message) back to A using the temporary route constructed in step 1, as shown in the following figure. This message is used by intermediate devices to establish a (permanent) route back to C.
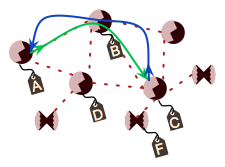
Because C is a one-hop neighbor, B does not need to store routing information about it. D is not involved in this part of the discovery process because it was not selected by A in the above step. When the message reaches device A, the route discovery is complete and the new route can be used to send data messages from A to C.
Zigbee PRO networks will detect asymmetric RF links and avoid them during route discovery. This improves the reliability of the discovery process and the resulting routes.
Routes that have not been used within a certain timeout period (1 minute in EmberZNet 3.0 and later) are marked for re-use and new routes may then overwrite that memory location. In some cases a new route may be needed and one or more intermediate devices will not have an available routing table entry; in this case the message will be reported as undeliverable to the sending node.
The application specifies if an end-to-end acknowledgment should be sent by the receiver (this is called an APS acknowledgment). If yes, the sender will be notified upon successful delivery of in the case of a timeout waiting for acknowledgment. In the case of a timeout, the route may need to be repaired.
Route Repair#
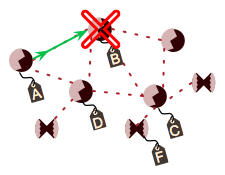
When a unicast message is sent with an acknowledgment requested, the sending device will be informed when the message is successfully delivered. If does not receive this acknowledgment, it can then take steps to repair the route. Route repair follows exactly the same steps as route discovery, above, but the damaged node (B, in the following figure) does not participate, resulting in a different route choice.
The routing table for A is updated to reflect that the next hop is D and the message is successfully delivered along the new path, as shown in the following figure.
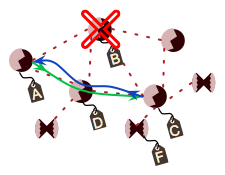
If no alternative path is available, the sender is informed that the message could not be delivered. In EmberZNet PRO this is denoted by a response with EmberStatus of EMBER_DELIVERY_FAILED (0x66).
EmberZNet PRO will attempt to deliver a message again before performing the route repair. Route repair is performed automatically when EMBER_APS_OPTION_RETRY and EMBER_APS_OPTION_ENABLE_ROUTE_DISCOVERY are both set in the message options.
Retries and Acknowledgements#
Zigbee and its underlying network layers provide a system of retries and acknowledgments that are designed to efficiently manage the uncertainty of RF communication. It is not necessary to understand this concept in order to start using Zigbee but it may be of interest to some application developers in specific situation.
This section discusses retries and acknowledgments layer-by-layer:
MAC retries and ACKs (802.15.4)
NWK retries (Zigbee NWK layer)
APS retries and ACKs (Zigbee APS layer)
MAC Retries and ACKs (802.15.4)#
The following figure illustrates the MAC layer transmission retry process.
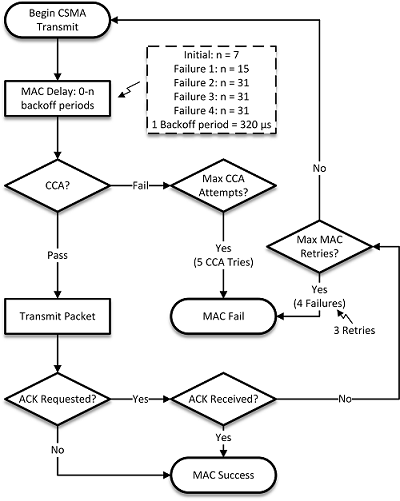
The MAC layer attempts transmission five times.
Unicast retries will occur if the channel was not clear (CCA fail) or if the MAC level ACK was not received from the next hop destination.
Broadcast retries will occur in the case of CCA failure but broadcast does not use the MAC ACK capability.
These retries occur very quickly — maximum retry time for complete failure is approximately 37 ms. Note that the MAC ACK is sent back immediately from the sender without additional CCA — see 802.15.4 documentation for more information.
NWK Retries#
NWK retries in Zigbee are vendor specific. The following figure illustrates the EmberZNet PRO stack’s NWK layer transmission retry process.

The NWK retries occur only if the MAC layer indicates a transmission failure. They operate on a longer time scale than MAC retries and therefore give the network additional robustness in the presence of medium term (1-500 ms) interference.
Silicon Labs’ interference research shows that the NWK layer retries are important for overcoming temporary interference from WiFi in certain situations.
Unicast: unicast behavior is as described in the flow chart, with retries for up to 500 ms.
Broadcast: broadcast messages are re-sent every 500 ms up to a total of 3 times (including the initial broadcast) or until all neighbors are heard to rebroadcast the message themselves (thereby ensuring complete delivery).
APS Retries and ACKs#
The following figure illustrates the APS layer retry process.
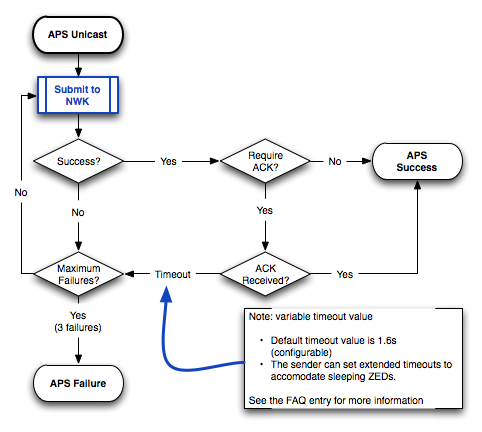
The APS layer has an ACK flag that controls whether it uses the additional logic to wait for an acknowledgment and retry if the acknowledgment is not heard. This represents a full end-to-end acknowledgment from the recipient device.
The APS layer can be further optionally configured to repair the route to the destination in the case that the APS sending fails.
There is no equivalent of the APS end-to-end acknowledgment for broadcast messages.
Conclusions#
If it is possible to send a message to the destination, the automatic Zigbee behavior provides "maximum effort", by attempting retries over several different time scales, from 1 ms to several seconds with optional end-to-end ACK and route repair.
If the delivery fails, the application is recommended to wait a more significant amount of time before retrying — this gives the interference or failure time to clear up. In cases of extreme bandwidth congestion the application retries may actually contribute to the problem.