Add Machine Learning to a New or Existing Project#
This guide provides details of adding Machine Learning to a new or existing project, making use of the wrapper APIs for TensorFlow Lite for Microcontrollers provided by Silicon Labs for automatic initialization of the TFLM framework.
The guide assumes that a project already exists in the Simplicity Studio workspace and you have installed the AI/ML extension. If you're starting from scratch, you may start with any sample application or the Empty C++ application. Please refer to AI/ML Extension Setup for instructions to install the AI/ML extension. TFLM has a C++ API, so the application code interfacing with it will also need to be written in C++. If you're starting with an application that is predominantly C code, see the section on interfacing with C code for tips on how to structure your project by adding a separate C++ file for the TFLM interface.
Install the TensorFlow Lite Micro Component#
Open your project file (the one with the
.slcpextension).
Under Software Components, search for "aiml".

Enable the AI/ML extension by clicking Enable Extension.

Expand: AI/ML > Machine Learning > TensorFlow. Select TensorFlow Lite Micro and click Install.
Note: Skip this step for SiWx917 applications.

You will be prompted to select additional components:
Note: Skip this step for SiWx917 applications.

Debug Logging: Choose Debug Logging using IO Stream (if needed) or Debug Logging Disabled. Click Install.
NOTE: If your project didn't already contain an I/O Stream implementation, you may get a dependency validation warning. This is not a problem, but simply means that a choice of I/O Stream backend needs to be made. The USART or EUSART backends are the most common, as these can communicate with a connected PC through the development kit virtual COM port (VCOM).
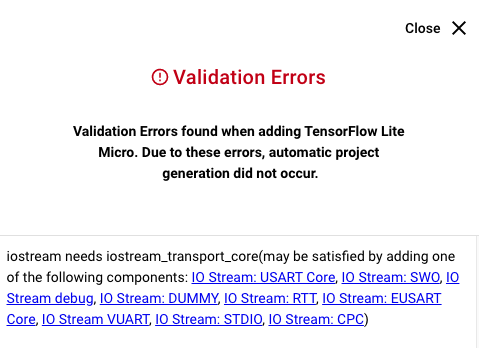
IO Stream: You may also need to install EUSART or USART component if you don't see output on your serial console.

Accept the default suggestion of "vcom" as the instance name, which will automatically configure the pinout to connect to the development board's VCOM lines. If you're using your own hardware, you can set any instance name and configure the pinout manually.
Kernels: Select MVPv1 Accelerated Kernels. Click Install.

Additional Software Components and C++ Build Settings#
Note: Skip to Model Inclusion section for Series 2 devices. This section is only applicable for SiWx917 devices.
Ensure the following components are installed in your project.
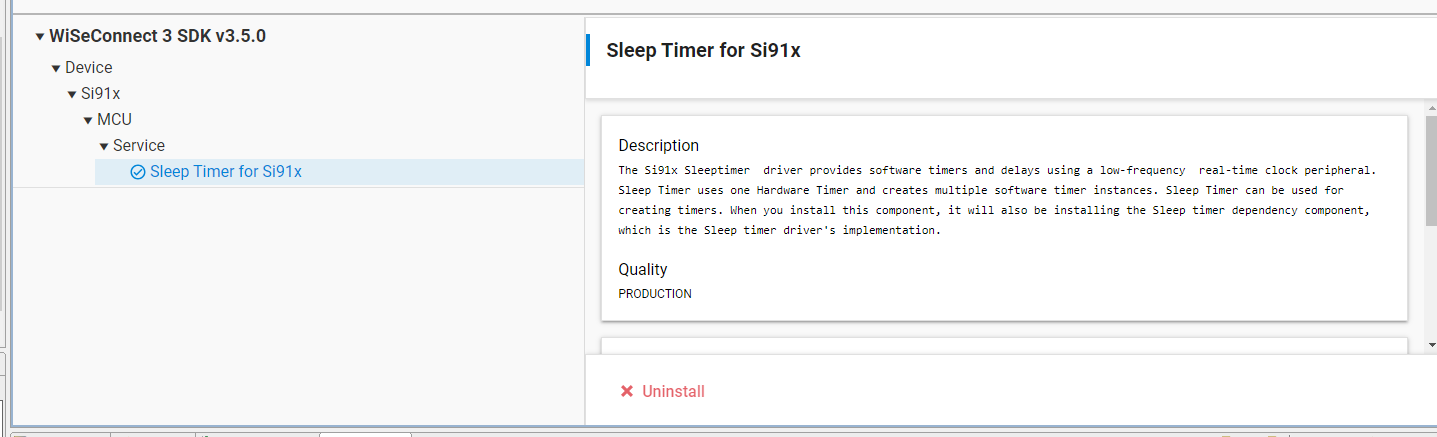
WiseConnect SDK > Device > Si91X > MCU > Service > Power Manager > Sleep Timer for Si91x
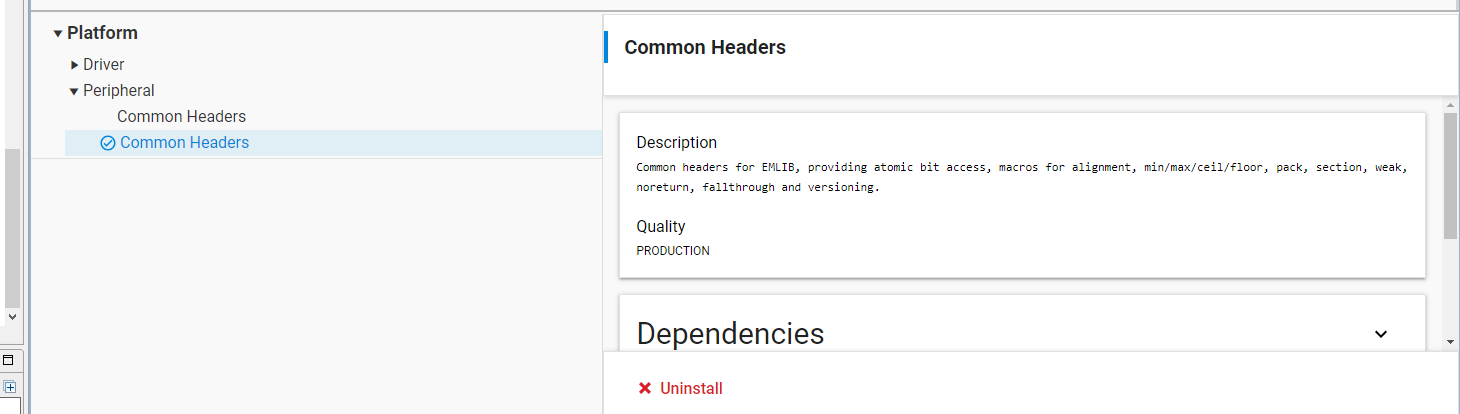
Platform > Peripheral > Common Headers
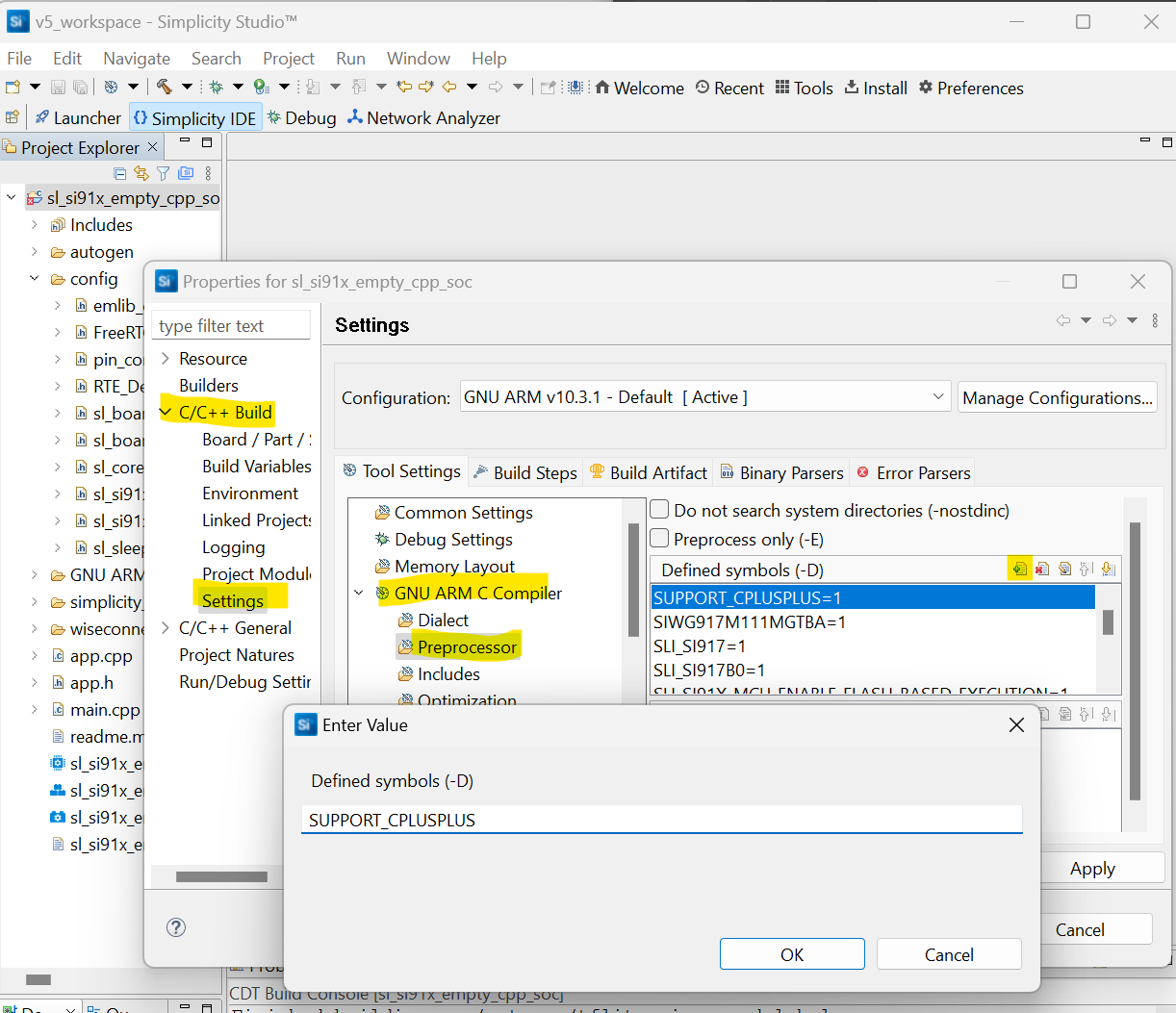
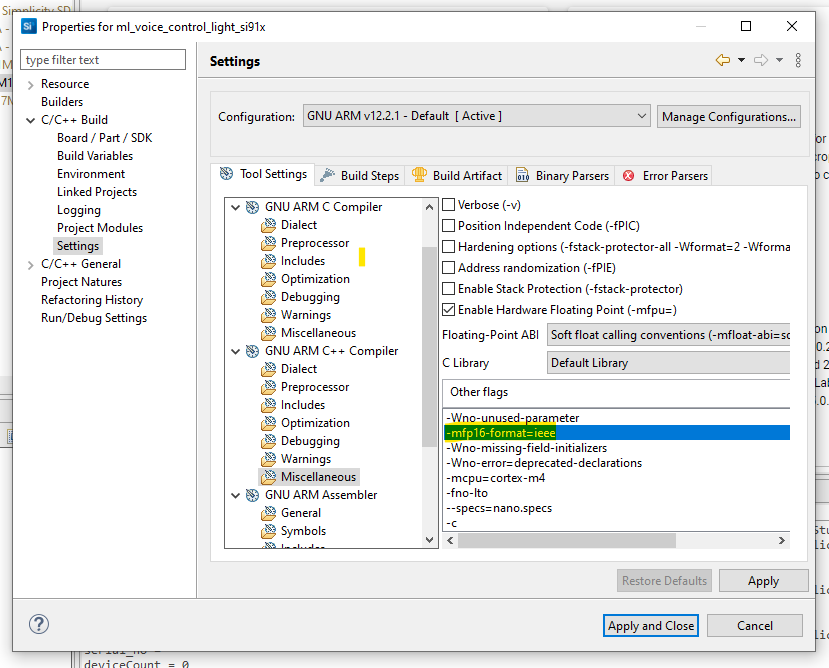
Update your C++ build settings as follows:
In the C preprocessor defines, add:
SUPPORT_CPLUSPLUS.In GNU ARM C++ Compiler > Miscellaneous settings, add:
-mfp16-format=ieee.
Alternate method:
You can also add these settings directly to your project's
.slcpfile:Open the
.slcpfile in a text editor.Add
SUPPORT_CPLUSPLUSto thedefinesection for C preprocessor defines. For example:define: - name: SUPPORT_CPLUSPLUS value: 1Add
-mfp16-format=ieeeto thetoolchain_settingssection for C++ compiler flags, for example:toolchain_settings: - option: gcc_compiler_option value: -mfp16-format=ieeeSave the file and regenerate your project to apply the changes.
Model Inclusion#
With the TensorFlow Lite Micro component added in the Project Configurator, the next step is to load the model file into the project. To do this, create a tflite directory inside the config directory of the project, and copy the .tflite model file into it. The project configurator provides a tool that will automatically convert .tflite files into sl_tflite_micro_model source and header files. The full documentation for this tool is available at Flatbuffer Converter Tool.
For SiWx917 devices, after copying the .tflite model file into the project, a header file named sl_ml_model_<model_name>.h is generated. This header provides access to the C array obtained from the converted .tflite file, as well as APIs to initialize and run the model.
Automatic Initialization#
The TensorFlow framework is automatically initialized using the system initialization framework described in SDK Programming Model. This includes allocating a tensor arena, instantiating an interpreter and loading the model.
Configuration#
Note: All configuration for SiWx917 is taken care of automatically.
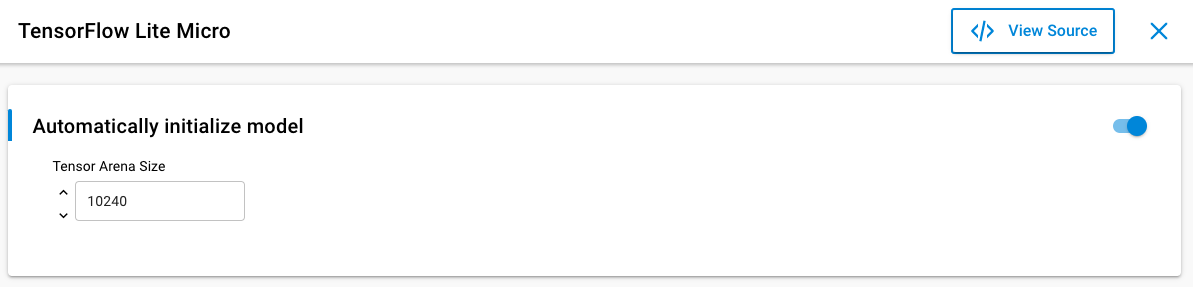
If the model was produced using the Silicon Labs Machine Learning Toolkit (MLTK), it already contains metadata indicating the required size of the Tensor Arena, the memory area used by TensorFlow for runtime storage of input, output, and intermediate arrays. The required size of the arena depends on the model used.
If not using the MLTK, the arena size needs to be configured. This can be done in two ways:
[Automatic] Set the arena size to -1, and it will attempt to automatically infer the size upon initialization.
[Manual] Start with a large number during development, and reduce the allocation until initialization fails as part of size optimization.

Run the Model for Series 2 Devices#
Include the Silicon Labs TensorFlow Init API#
#include "sl_tflite_micro_init.h"For default behavior in bare metal application, it is recommended to run the model during app_process_action() in app.cpp to ensure that periodic inferences occur during the standard event loop. Running the model involves three stages:
Provide Input to the Interpreter#
Sensor data is pre-processed (if necessary) and then is provided as input to the interpreter.
TfLiteTensor* input = sl_tflite_micro_get_input_tensor();
// stores 0.0 to the input tensor of the model
input->data.f[0] = 0.;Run Inference#
The interpreter is then invoked to run all layers of the model.
TfLiteStatus invoke_status = sl_tflite_micro_get_interpreter()->Invoke();
if (invoke_status != kTfLiteOk) {
TF_LITE_REPORT_ERROR(sl_tflite_micro_get_error_reporter(),
"Bad input tensor parameters in model");
return;
}Read Output for Series 2 devices#
The output prediction is read from the interpreter.
TfLiteTensor* output = sl_tflite_micro_get_output_tensor();
// Obtain the output value from the tensor
float value = output->data.f[0];At this point, application-dependent behavior based on the output prediction should be performed. The application will run inference on each iteration of app_process_action().
Full Code Snippet (Series 2)#
After following the steps above, the resulting app.cpp now appears as follows:
#include "sl_tflite_micro_init.h"
/***************************************************************************//**
* Initialize application.
******************************************************************************/
void app_init(void)
{
// Init happens automatically
}
/***************************************************************************//**
* App ticking function.
******************************************************************************/
void app_process_action(void)
{
TfLiteTensor* input = sl_tflite_micro_get_input_tensor();
// stores 0.0 to the input tensor of the model
input->data.f[0] = 0.;
TfLiteStatus invoke_status = sl_tflite_micro_get_interpreter()->Invoke();
if (invoke_status != kTfLiteOk) {
TF_LITE_REPORT_ERROR(sl_tflite_micro_get_error_reporter(),
"Bad input tensor parameters in model");
return;
}
TfLiteTensor* output = sl_tflite_micro_get_output_tensor();
// Obtain the output value from the tensor
float value = output->data.f[0];
}Run the Model for SiWx917 Devices#
For SiWx917 devices, the APIs differ from Series 2. Use the generated model C++ APIs to initialize and run your model. Below is a general guide for using these APIs:
Include Required Headers
//Provides _init() and _run() functions for this model #include "sl_ml_model_<model_name>.h" // ...other headers as needed...System Initialization
sl_system_init();Model Initialization
//Loads and Initializes the model with name <model_name> //Initializes its parameters //Initializes its interpreter //Initializes its error reporter //Allocates memory for model's tensors sl_status_t status = slx_ml_<model_name>_model_init(); if (status != SL_STATUS_OK) { printf("Failed to initialize model\n"); // Handle error }Access and Prepare Input Tensors
for (unsigned int i = 0; i < <model_name>_model.n_inputs(); ++i) { auto& input_tensor = *<model_name>_model.input(i); // Fill input_tensor.data with your input data }Run Inference
/// Executes the model with name <model_name> by invoking its interpreter for TFLite Micro and returns execution status. /// The output is stored in the output tensor of the model itself. status = slx_ml_model_<model_name>_run(); if (status != SL_STATUS_OK) { printf("Error while running inference\n"); // Handle error }Access Output Tensors
for (unsigned int i = 0; i < <model_name>_model.n_outputs(); ++i) { auto& output_tensor = *<model_name>_model.output(i); // Read results from output_tensor.data }
Full Code Snippet (SiWx917)#
Below is a generic code snippet for running a model on SiWx917 devices. Replace <model_name> with your actual model name.
app.h
#ifndef APP_H
#define APP_H
#ifdef __cplusplus
extern "C" {
#endif
void app_init(void);
void app_process_action(void);
#ifdef __cplusplus
}
#endif
#endif // APP_Happ.cc#
#include "app.h"
#include "model_runner.h"
sl_status_t <model_name>_model_status = SL_STATUS_OK;
// Initialization logic
void app_init(void) {
<model_name>_model_status = model_runner_init();
if (<model_name>_model_status != SL_STATUS_OK) {
// Print helpful error message or handle error
return;
}
}
void app_process_action(void) {
if (<model_name>_model_status != SL_STATUS_OK) {
// Print an error message or indicate error
return;
}
model_runner_loop();
}model_runner.cc#
#include "sl_ml_model_<model_name>.h"
sl_status_t model_runner_init(void) {
// Peripheral and other initialization logic
<model_name>_model_status = slx_ml_<model_name>_model_init();
if (<model_name>_model_status != SL_STATUS_OK) {
// Peripheral deinit or cleanup logic
return SL_STATUS_FAIL;
}
return <model_name>_model_status;
}
sl_status_t model_runner_loop(void) {
// Data capture and pre-processing logic
<model_name>_model_status = slx_ml_<model_name>_model_run();
if (<model_name>_model_status != SL_STATUS_OK) {
// Peripheral deinit or cleanup logic
return SL_STATUS_FAIL;
}
// Post-processing logic
return <model_name>_model_status;
}Addendum: Interfacing with C Code#
If your project is written in C rather than C++, place the code interfacing with TFLM into a separate file that exports a C API through an interface header. For this example, a filename app_ml.cpp is assumed that implements the function ml_process_action() with the same content as in the example above.
app_ml.h#
#ifdef __cplusplus
extern "C" {
#endif
void ml_process_action(void);
#ifdef __cplusplus
}
#endifapp_ml.cpp#
#include "app_ml.h"
#include "sl_tflite_micro_init.h"
extern "C" void ml_process_action(void)
{
// ...
}app.c#
#include "app_ml.h"
// ...
void app_process_action(void)
{
ml_process_action();
}Addendum: Series 2 to SiWx917 (and vice versa) App Conversion#
If you need to port an application from Series 2 to SiWx917, first remove the TensorFlow Lite Micro component from your project. Then, follow these steps for adding the required software components and C++ build settings. For SiWx917 devices, the APIs and workflow differ from Series 2. Use the generated model C++ APIs as described in the Run the Model for SiWx917 Devices section above. Refer to the provided code snippets and step-by-step instructions on this page for details on initialization, running inference, and accessing input/output tensors. For a complete example, see the Full Code Snippet (SiWx917) section. After updating your project, regenerate it to ensure all dependencies are correctly configured.