Memory Segments and LIB Heap#
Memory Segments#
A memory segment is a type construct that is used to describe a memory region having particular properties that will be used to allocate data at run-time. It can be as simple as a table with no constraints, or as complex as DMA-accessible or cache-capable regions, with special considerations for cache line size, padding, and alignment.
Several functions can be used to allocate data from memory segments. These functions are all part of the LIB Mem sub-module of Common and include functions such as Mem_SegAlloc(), Mem_DynPoolCreate(), Mem_DynPoolBlkGet(), and others. Each of these functions will allocate data using specific parameters, be they parameters passed at segment creation, pool creation, or directly at the function call. Please refer to the Memory Allocation Guide page for more information.
Memory Segment Allocation#
Memory segment allocation calls include Mem_SegAlloc(), Mem_SegAllocExt() and Mem_SegAllocHW(). Each of these functions works in a similar fashion where they allocate a chunk of memory from a particular memory segment that can then be used to store any kind of data. The memory allocated this way is not allowed to be freed, since this would lead to fragmentation problems, and would require to keep a list of blocks available for a re-allocation, which would increase the amount of memory required by LIB.
The three flavors of the memory segment allocation functions can be used in different situations. Mem_SegAlloc() is the simplest one. Mem_SegAllocExt(), by comparison, allows you to specify more parameters, such as the alignment of the allocated block, or a pointer to the number of bytes missing for an allocation to succeed. Mem_SegAllocHW() is a bit different from the others two because it takes into account the padding alignment specified at segment creation when allocating blocks of data. This is to make sure blocks are not located on the same cache lines, to facilitate flush, and invalidate operations when the memory allocated this way is accessed via DMA.
Several usage scenarios, and more details on memory segment allocations, are provided in the Memory Segment Allocations page. These scenarios will indicate where in a memory segment the allocations are located depending on various parameters.
Dynamic Memory Pools#
Dynamic memory pools are constructs that are used to allocate and free blocks of the same size. These blocks are allocated from a memory segment. At its creation, the pool can already have an initial number of blocks allocated, and can have either a maximum number of blocks allocatable or no maximum at all, limited only by available space in the memory segment. For example, this allows pools to have a fixed amount of blocks all allocated at creation, or no blocks allocated at creation and an allocation only when needed.
There are three functions that can create a dynamic memory pool: Mem_DynPoolCreate(), Mem_DynPoolCreatePersistent() and Mem_DynPoolCreateHW(). As for the memory segment allocation, the Mem_DynPoolCreateHW() flavor takes into account the padding alignment specified at the creation of the memory segment to make sure no two blocks are on the same cache line.
One of the differences between Mem_DynPoolCreate() and Mem_DynPoolCreatePersistent() is that blocks allocated by Mem_DynPoolCreate() are not guaranteed to keep their data when freed and reallocated, while those allocated by Mem_DynPoolCreatePersistent() do keep their data. Also, blocks allocated by Mem_DynPoolCreatePersistent() can have a callback associated with them that is called once for every newly-allocated block, allowing to data to be set at that moment.
Several usage scenarios and more details on dynamic memory pools are provided in the Dynamic Memory Pools page. These scenarios will indicate where in a memory segment the allocations are located depending on various parameters.
LIB Heap#
The LIB Heap is a particular memory segment that can be provided by the LIB Mem sub-module of Common. It is a normal memory segment, which acts exactly the same way as the other memory segments detailed above. Its size, padding alignment, and base address can all be configured in common_cfg.h, as detailed in the LIB Heap configuration page. It will be used by default by various stacks and products, or if the caller passes DEF_NULL when a memory segment pointer is required as a parameter.
Dynamic Memory Pools#
This page provided in-depth information about the various types of dynamic memory pools that you can use to allocate and free fixed-size blocks from a memory segment.
Usage Scenarios#
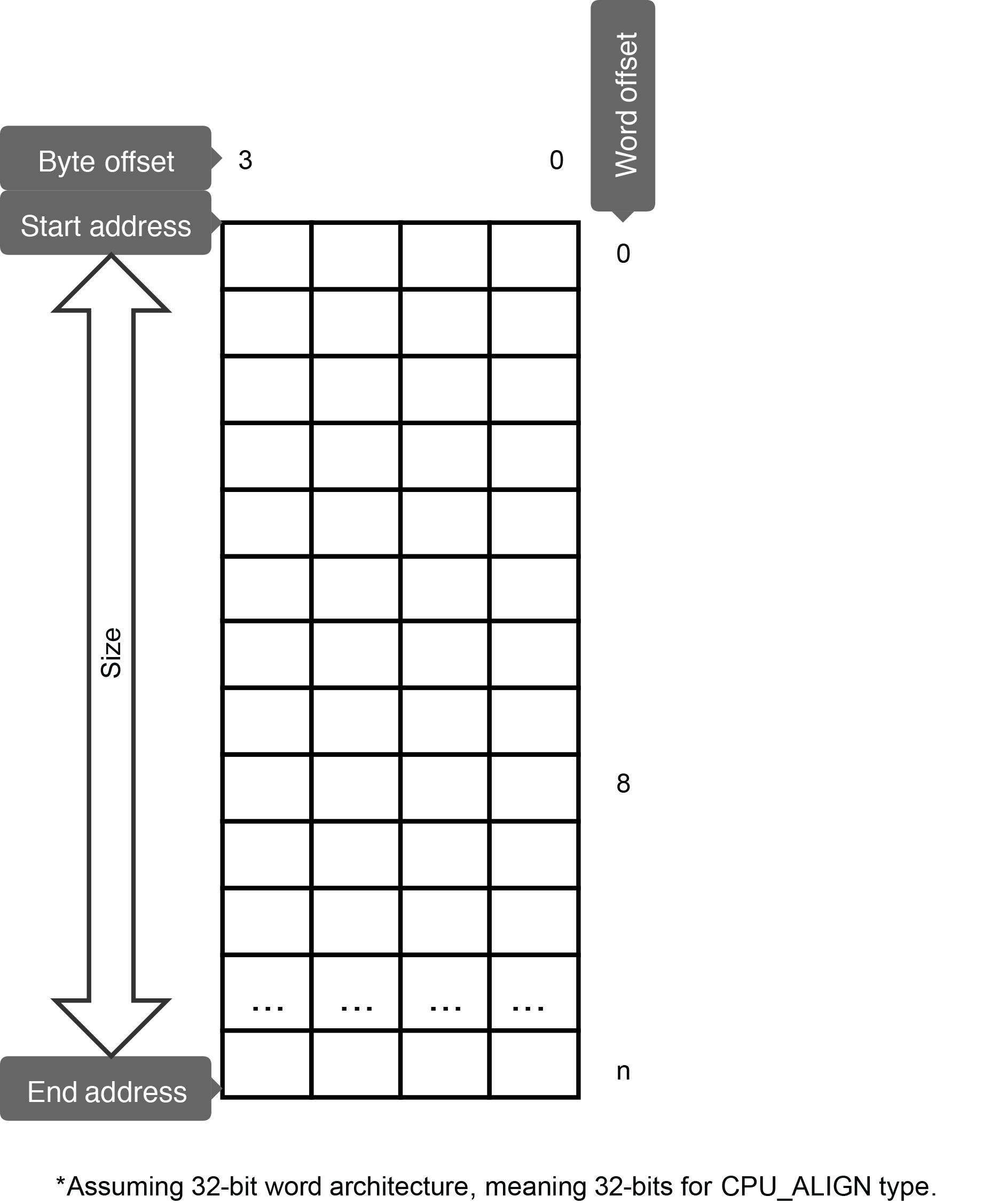
The Figure - Empty MEM_SEG representation in the Dynamic Memory Pools page represents a new, empty memory segment. We will assume a 32-bit architecture for all of the following examples. That means that the size of the CPU_ALIGN type is 32, which is used by default in some allocation cases. In this figure, the bytes increase from right to left and the memory addresses grow from top to bottom.
Figure - Empty MEM_SEG representation#
Dynamic Memory Pools#
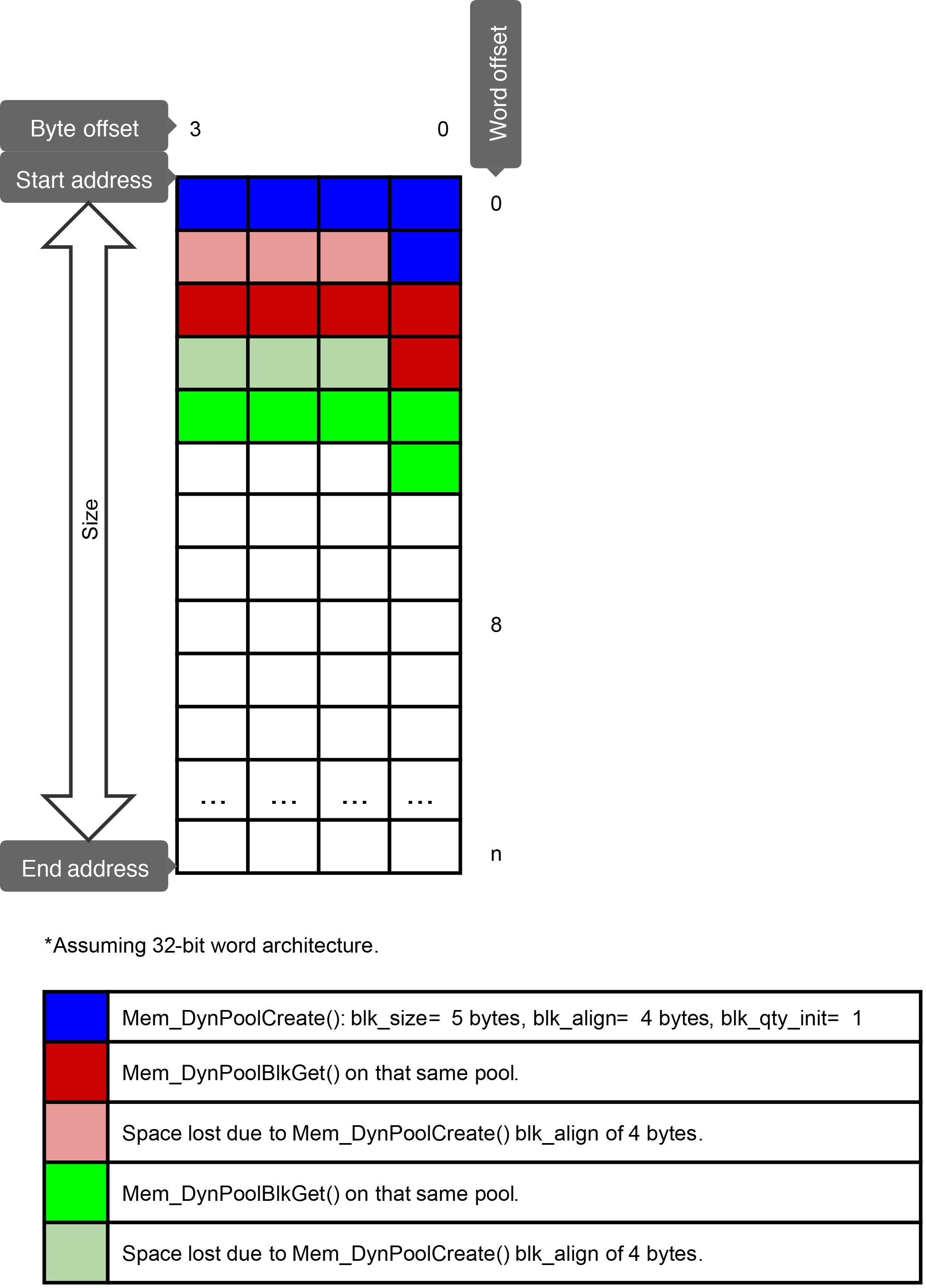
The Figure - Mem DynPoolCreate() and Mem DynPoolBlkGet() in the Dynamic Memory Pools page shows a call to Mem_DynPoolCreate() (or Mem_DynPoolCreatePersistent(), which works the same way) with an initial block value of 1, meaning it will allocate one single block during pool creation, followed by two calls to Mem_DynPoolBlkGet(), on that same pool. The block size is set to 5 bytes and the block alignment to 4 bytes. The initial call to Mem_DynPoolCreate() allocates the first 5-byte block, in blue. The following Mem_DynPoolBlkGet() call will need to sacrifice three bytes to align the second block on an 8-byte boundary, and the same can be said for the third call.
This means that, in this particular case, with an alignment of 8 and no interleaved allocation calls (other pools allocating blocks or Mem_SegAlloc...() calls) on that segment, both 8-byte blocks and 5-byte blocks use up the same amount of space in the segment. Knowing that it is possible to use 3 more bytes per block without actually using more memory, it may be possible to optimize the code to make use of these three additional bytes. Or, knowing that the alignment of each block is 4, it might be possible to scale down each block to 4 bytes instead of 5, saving 3 extra bytes for every block.
Figure - Mem_DynPoolCreate() and Mem_DynPoolBlkGet()#
Listing - Dynamic memory pools code snippet#
#define MY_MEM_SEG_DATA_SIZE 64u
CPU_INT08U MyMemSegData[MY_MEM_SEG_DATA_SIZE];
MEM_SEG MyMemSeg;
MEM_DYN_POOL MyMemDynPool;
/* ... */
static void MyCreationFnct (void)
{
RTOS_ERR err;
Mem_SegCreate("My mem seg",
&MyMemSeg,
(CPU_ADDR)&MyMemSegData[0u],
MY_MEM_SEG_DATA_SIZE,
LIB_MEM_PADDING_ALIGN_NONE,
&err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
Mem_DynPoolCreate("My mem dyn pool",
&MyMemDynPool,
&MyMemSeg,
5u,
4u,
1u,
LIB_MEM_BLK_QTY_UNLIMITED,
&err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
}
/* ... */
static void MyAlloctionFnct (void)
{
CPU_INT08U *p_blk_1;
CPU_INT08U *p_blk_2;
RTOS_ERR err;
p_blk_1 = (CPU_INT08U *)Mem_DynPoolBlkGet(&MyMemDynPool, &err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
p_blk_2 = (CPU_INT08U *)Mem_DynPoolBlkGet(&MyMemDynPool, &err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
}Persistent Dynamic Memory Pools#
Persistent pools, which can be created by calling Mem_DynPoolCreatePersistent(), are very similar to regular dynamic memory pools but for a few notable exceptions.
First, they require an extra pointer to be allocated for each block, meaning that if the caller requires a 14-byte block for a persistent pool, the actual amount of memory allocated will be 18 bytes (on a 32-bit architecture). But this requirement provides a potentially useful advantage: once allocated, the block's content will never be altered, even while it is freed. With regular pools, between a Mem_DynPoolBlkFree() and a subsequent Mem_DynPoolBlkGet(), a block's content is not guaranteed to remain the same, since part of it is used for maintaining the "free blocks" list.
The third and final difference with persistent pools is that a callback function and an argument can be passed during the pool's creation. After this, for every new block created (not ones freed and then re-obtained), the callback will be executed. This is particularly useful if every block needs to hold some persistent data such as a kernel object, more allocated data, or anything difficult or impossible to free. With persistent pools, you need only allocate or create whatever data that needs to be persistent in the callback, and the block will be able to hold it for as long as required, even if the block is freed and re-obtained at some point.
Hardware Dynamic Memory Pools#
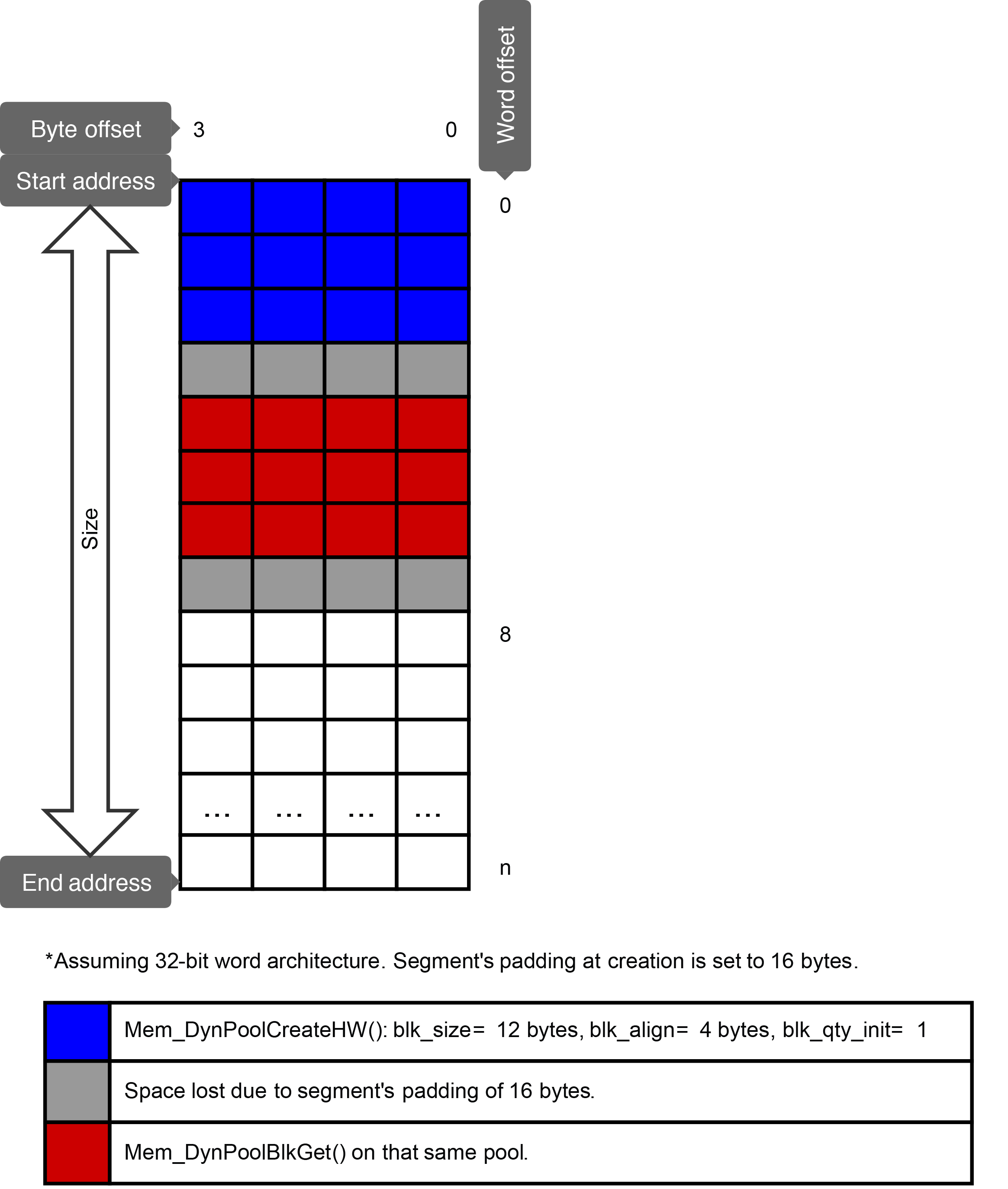
The Figure - Mem_DynPoolCreateHW() and Mem_DynPoolBlkGet() calls in the Dynamic Memory Pools page shows the result of two functions calls: First, a call to Mem_DynPoolCreateHW(), which takes into account the segment's padding alignment; and second, a call to Mem_DynPoolBlkGet(), which allocates another block from that same pool. The segment's padding alignment (as specified during segment creation) is set to 16 bytes, while the pool has a block size of 12, a block alignment of 4, and an initial quantity of 1.
The first block allocated uses 12 bytes, and pads for the 16-byte alignment of the segment. The subsequent call to Mem_DynPoolBlkGet() does the same thing, resulting in a total of 32 bytes used in memory for two 12-byte blocks. We can see that, since the segment's padding of 16 is an even multiple of the block alignment of 4, the next block naturally falls on a 4-byte boundary requiring no adjustment. This might not have been the case if another allocation had been made between those two calls, which is why it is important to provide the block alignment nonetheless.
Knowing how these blocks are allocated could help to optimize the code by giving each block 4 extra bytes that it always uses in order to conform to the segment's padding alignment constraint, which is a bit like the case with Mem_DynPoolCreate() mentioned above. But, contrary to the previous example, reducing the block size (if possible) would not be beneficial, since the padding alignment would still require a 16-byte boundary, meaning that the minimum size of an allocation on that segment is 16 bytes, not less.
Figure - Mem_DynPoolCreateHW() and Mem_DynPoolBlkGet() calls#
Listing - Hardware dynamic memory pools code snippet#
#define MY_MEM_SEG_DATA_SIZE 64u
CPU_INT08U MyMemSegData[MY_MEM_SEG_DATA_SIZE];
MEM_SEG MyMemSeg;
MEM_DYN_POOL MyMemDynPool;
/* ... */
static void MyCreationFnct (void)
{
RTOS_ERR err;
Mem_SegCreate("My mem seg",
&MyMemSeg,
(CPU_ADDR)&MyMemSegData[0u],
MY_MEM_SEG_DATA_SIZE,
16u,
&err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
Mem_DynPoolCreateHW("My mem dyn pool",
&MyMemDynPool,
&MyMemSeg,
12u,
4u,
1u,
LIB_MEM_BLK_QTY_UNLIMITED,
&err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
}
/* ... */
static void MyAlloctionFnct (void)
{
CPU_INT08U *p_blk_1;
RTOS_ERR err;
p_blk_1 = (CPU_INT08U *)Mem_DynPoolBlkGet(&MyMemDynPool, &err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
}Multiple Dynamic Memory Pools Calls#
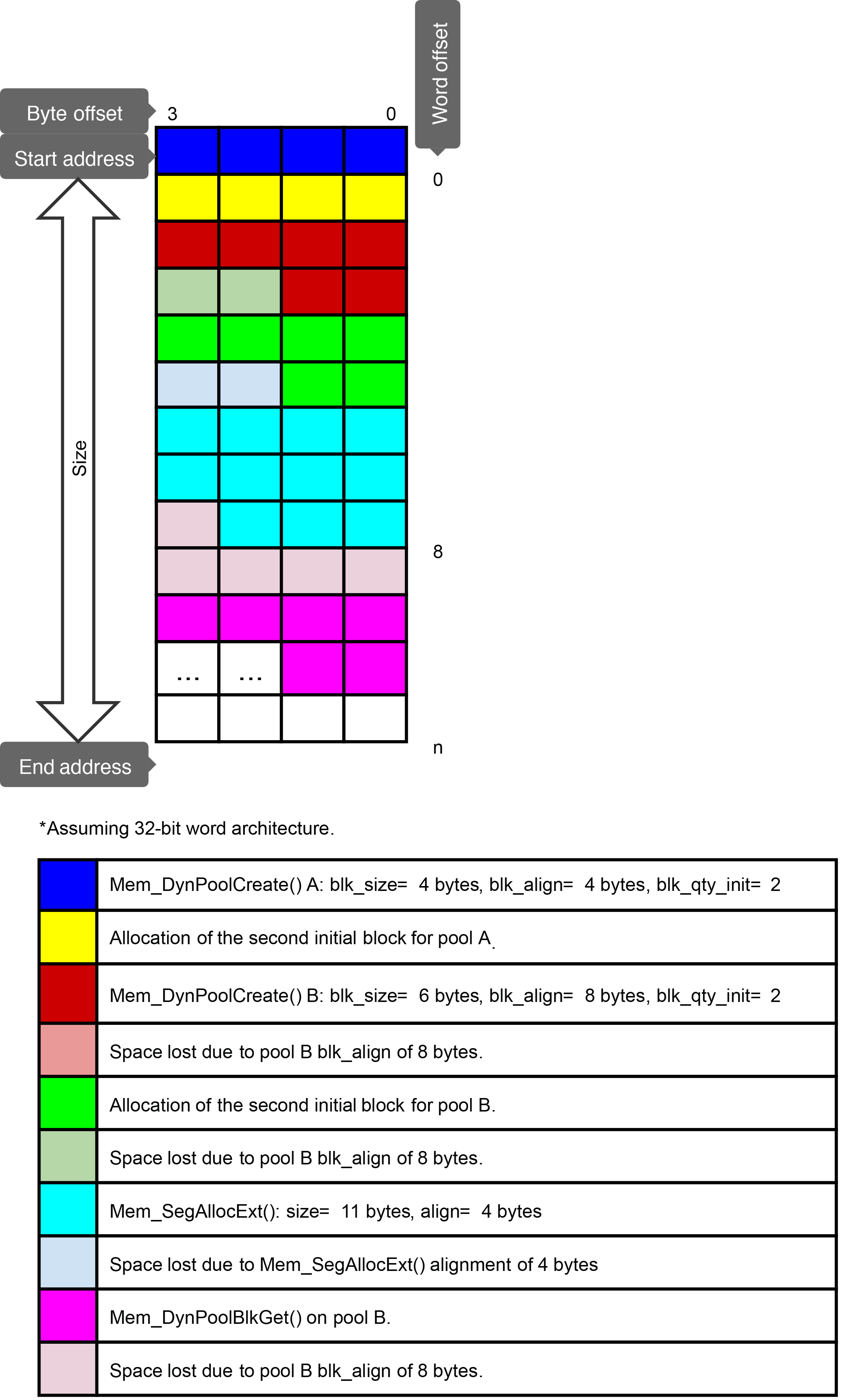
The Figure - Several Mem_DynPoolCreate() and Mem_DynPoolBlkGet() in the Dynamic Memory Pools page shows two calls to Mem_DynPoolCreate(), followed by a series of calls to Mem_DynPoolBlkGet() on each of the two created pools. Pool A has a block size and alignment requirement of 4 bytes and an initial quantity of 1. Pool B has a block size of 6 and a block alignment requirement of 8, with two initial blocks allocated. The figure shows that the initial block for pool A is allocated first in the segment, followed by the first two blocks of pool B. Then pool A allocates another block, followed by another in pool B, and a final one in pool A.
The result is that 44 bytes of memory have been used even though the various callers asked for only 30 bytes. It is easy to see that if the pool A allocations been grouped together (or at least if the second block had been made at pool creation), no memory would have been wasted, as the block size is 4 with an alignment of 4. Every block allocated from pool B still takes at least 2 bytes more than required, since every other allocation is aligned minimally on 4 bytes and the pool B blocks have a size of 6.
If all the blocks from pool A had been grouped, followed by allocation of blocks from pool B, the amount of memory used could have been reduced to 38–42 bytes, depending on the subsequent allocation alignment. If it were also possible to allocate the second pool A block at creation, and leave the others identical, the amount of memory used would have been reduced to 36 bytes.
This example shows how it is possible to optimize some cases, when block size and alignment are known beforehand. It is not possible to know exactly in every case how many blocks are needed to be used, but by using an initial value near (but not above) the estimated amount, it is possible to reduce the amount of memory lost due to padding or alignment constraints.
Figure - Several Mem_DynPoolCreate() and Mem_DynPoolBlkGet()#

Listing - Several dynamic memory pools code snippet#
#define MY_MEM_SEG_DATA_SIZE 64u
CPU_INT08U MyMemSegData[MY_MEM_SEG_DATA_SIZE];
MEM_SEG MyMemSeg;
MEM_DYN_POOL MyMemDynPoolA;
MEM_DYN_POOL MyMemDynPoolB;
/* ... */
static void MyCreationFnct (void)
{
RTOS_ERR err;
Mem_SegCreate("My mem seg",
&MyMemSeg,
(CPU_ADDR)&MyMemSegData[0u],
MY_MEM_SEG_DATA_SIZE,
LIB_MEM_PADDING_ALIGN_NONE,
&err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
Mem_DynPoolCreate("My mem dyn pool A",
&MyMemDynPoolA,
&MyMemSeg,
4u,
4u,
1u,
LIB_MEM_BLK_QTY_UNLIMITED,
&err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
Mem_DynPoolCreate("My mem dyn pool B",
&MyMemDynPoolB,
&MyMemSeg,
6u,
8u,
2u,
LIB_MEM_BLK_QTY_UNLIMITED,
&err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
}
/* ... */
static void MyAlloctionFnct (void)
{
CPU_INT08U *p_blk_1;
CPU_INT08U *p_blk_2;
CPU_INT08U *p_blk_3;
RTOS_ERR err;
p_blk_1 = (CPU_INT08U *)Mem_DynPoolBlkGet(&MyMemDynPoolA, &err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
p_blk_2 = (CPU_INT08U *)Mem_DynPoolBlkGet(&MyMemDynPoolB, &err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
p_blk_3 = (CPU_INT08U *)Mem_DynPoolBlkGet(&MyMemDynPoolA, &err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
}Mixed Usage#
The Figure - Mixed usage in the Dynamic Memory Pools page shows the same example as the one above featuring the multiple pool calls. But in this case, a call to Mem_SegAlloc() is executed after the second call to Mem_DynPoolCreate(). It shows how a segment can be used to allocate different kinds of data, and how they can all be interleaved together in a single segment.
Of course, allocating several forms of data with varying padding and alignment requirements can lead to more memory space lost due to conflicting alignment constraints. Also, this figure shows how some blocks can end up spatially disconnected. For example, the third block from pool A could end up being allocated far from the first two, which would make it less likely that they could all be cached together, leading to code that could still be optimized.
Figure - Mixed usage#
Listing - Mixed usage code snippet#
#define MY_MEM_SEG_DATA_SIZE 64u
CPU_INT08U MyMemSegData[MY_MEM_SEG_DATA_SIZE];
MEM_SEG MyMemSeg;
MEM_DYN_POOL MyMemDynPoolA;
MEM_DYN_POOL MyMemDynPoolB;
/* ... */
static void MyCreationFnct (void)
{
RTOS_ERR err;
Mem_SegCreate("My mem seg",
&MyMemSeg,
(CPU_ADDR)&MyMemSegData[0u],
MY_MEM_SEG_DATA_SIZE,
LIB_MEM_PADDING_ALIGN_NONE,
&err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
Mem_DynPoolCreate("My mem dyn pool A",
&MyMemDynPoolA,
&MyMemSeg,
4u,
4u,
2u,
LIB_MEM_BLK_QTY_UNLIMITED,
&err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
Mem_DynPoolCreate("My mem dyn pool B",
&MyMemDynPoolB,
&MyMemSeg,
6u,
8u,
2u,
LIB_MEM_BLK_QTY_UNLIMITED,
&err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
}
/* ... */
static void MyAlloctionFnct (void)
{
CPU_INT08U *p_data_1;
CPU_INT08U *p_blk_1;
RTOS_ERR err;
p_data_1 = (CPU_INT08U *)Mem_SegAllocExt("allocation 1",
&MyMemSeg,
11u,
4u,
DEF_NULL,
&err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
p_blk_1 = (CPU_INT08U *)Mem_DynPoolBlkGet(&MyMemDynPoolA, &err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
}Final Words#
The various scenarios explained above provide a detailed view of the internals of allocating data using memory segments, as well as several hints about how it is possible to optimize memory usage if certain conditions are met.
Of course, run-time allocation is made during run-time simply because the amount and type of data needed is not known at compile-time. However, by planning the order of the memory segment's allocations, and adapting the size of the allocation when possible, or carefully choosing the properties of the memory segments themselves, it may be possible to optimize the amount of memory used. Or you can at least reduce the amount of memory lost, and convert it to memory that could be used for other purposes at no additional cost.
Memory Segment Allocations#
This page provides in-depth information about the various methods used to allocate memory blocks from a memory segment.
Usage Scenarios Details#
Figure - Empty MEM_SEG representation in the Memory Segment Allocations page represents a new, empty memory segment. We will assume a 32-bit architecture for all of the following examples, which also leads to a size of 32 for the CPU_ALIGN type, and which is used by default in some allocation cases. In this figure, the bytes increase from right to left and the memory addresses grow from top to bottom.
Figure - Empty MEM_SEG representation#
Memory Segment Allocations#
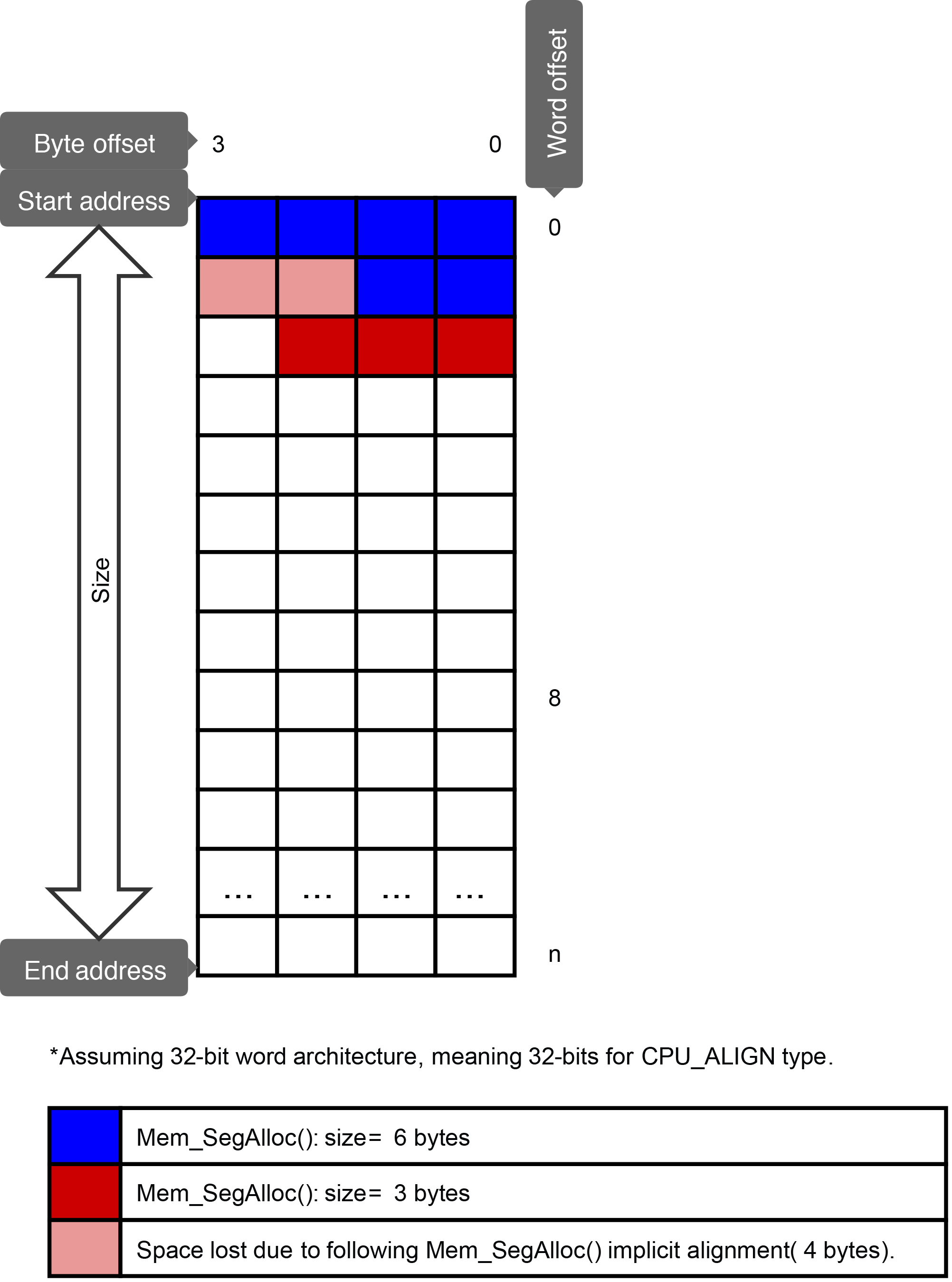
Figure - Mem SegAlloc() in the Memory Segment Allocations page shows two calls to Mem_SegAlloc(). The first, in blue, simply allocates the needed data (6 bytes), with no alignment required. Since the implicit memory alignment used when calling Mem_SegAlloc() is sizeof(CPU_ALIGN) (which is 4, in a 32-bit architecture), the second call (in bright red) needs to align itself on a 4-byte boundary. This means sacrificing 2 bytes (in pale red) to meet the alignment requirement. After this call, if a third call is made, it would need to sacrifice one byte in order to be aligned on a 4-byte boundary as well.
Figure - Mem_SegAlloc()#
Listing - Mem_SegAlloc() code snippet#
#define MY_MEM_SEG_DATA_SIZE 64u
CPU_INT08U MyMemSegData[MY_MEM_SEG_DATA_SIZE];
MEM_SEG MyMemSeg;
/* ... */
static void MyCreationFnct (void)
{
RTOS_ERR err;
Mem_SegCreate("My mem seg",
&MyMemSeg,
(CPU_ADDR)&MyMemSegData[0u],
MY_MEM_SEG_DATA_SIZE,
LIB_MEM_PADDING_ALIGN_NONE,
&err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
}
/* ... */
static void MyAlloctionFnct (void)
{
CPU_INT08U *p_data_1;
CPU_INT08U *p_data_2;
RTOS_ERR err;
p_data_1 = (CPU_INT08U *) Mem_SegAlloc("allocation 1",
&MyMemSeg,
6u,
&err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
p_data_2 = (CPU_INT08U *) Mem_SegAlloc("allocation 2",
&MyMemSeg,
3u,
&err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
}Extended Memory Segment Allocations#
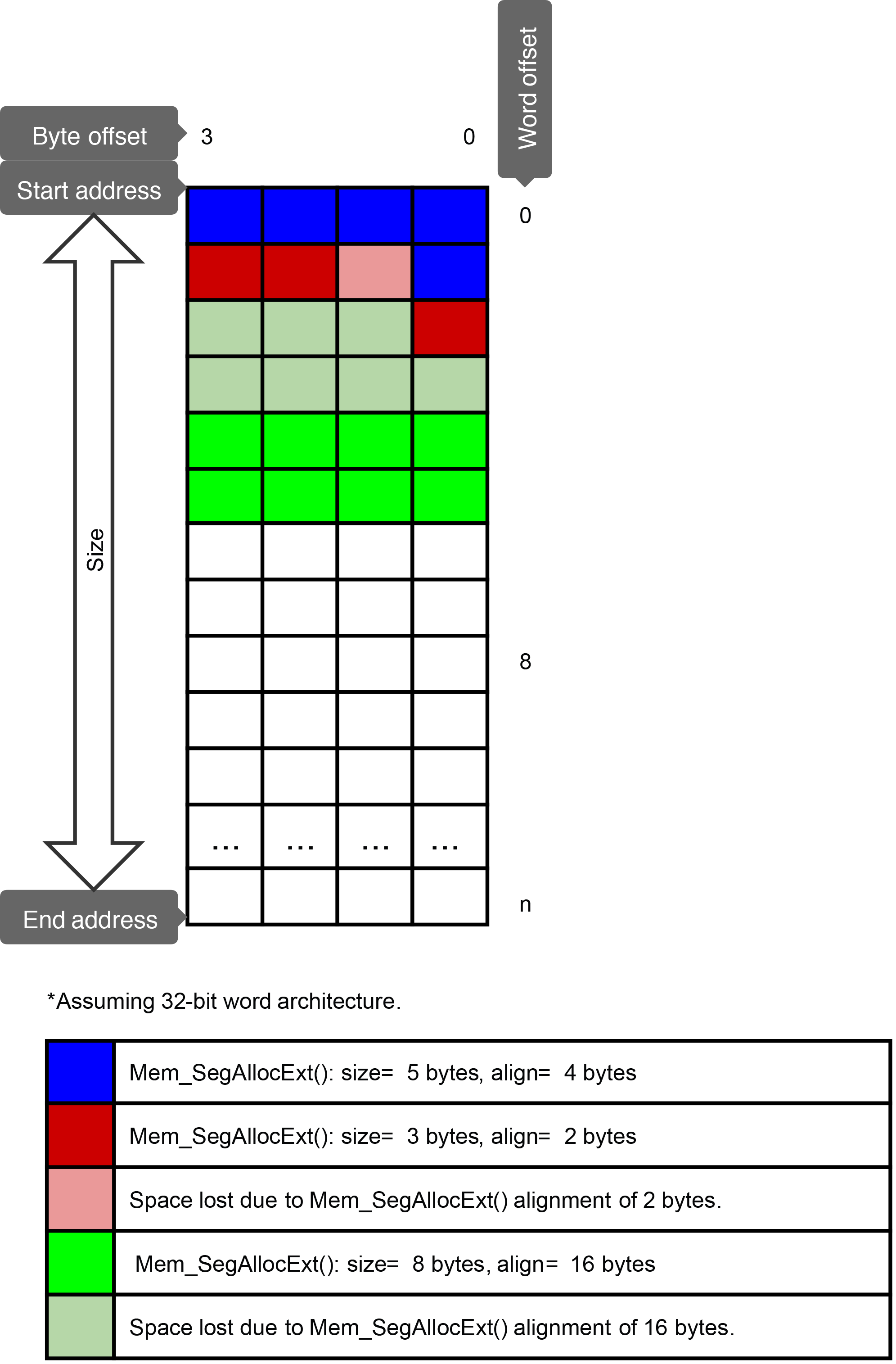
Figure - Mem_SegAllocExt() in the Memory Segment Allocations page shows three calls made to Mem_SegAllocExt(), which allows you to specify the memory block alignment for each call yourself. But varying the alignment value without forethought can produce unexpected results.
The first call simply allocates the data, which is 5 bytes. The second call, needing to be aligned on a 2-byte boundary, sacrifices a byte before allocating the requested data, which is 3 bytes. Finally, the third call, which requires a 16-byte alignment, sacrifices 7 bytes in order to align its allocated memory on a 16-byte boundary.
When these allocations are executed in that order, we end up using 24 bytes of memory for 16 usable, correctly-aligned bytes. When the alignment constraints vary greatly between allocation calls, you should consider the order in which you perform these calls, or try to adjust the size allocated, to save memory space. For example, by swapping the second and third calls, you would end up using only 19 bytes of memory to have 16 correctly-aligned, usable bytes.
Figure - Mem_SegAllocExt()#
Listing - Mem_SegAllocExt() code snippet#
#define MY_MEM_SEG_DATA_SIZE 64u
CPU_INT08U MyMemSegData[MY_MEM_SEG_DATA_SIZE];
MEM_SEG MyMemSeg;
/* ... */
static void MyCreationFnct (void)
{
RTOS_ERR err;
Mem_SegCreate("My mem seg",
&MyMemSeg,
(CPU_ADDR)&MyMemSegData[0u],
MY_MEM_SEG_DATA_SIZE,
LIB_MEM_PADDING_ALIGN_NONE,
&err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
}
/* ... */
static void MyAlloctionFnct (void)
{
CPU_INT08U *p_data_1;
CPU_INT08U *p_data_2;
CPU_INT08U *p_data_3;
RTOS_ERR err;
p_data_1 = (CPU_INT08U *) Mem_SegAllocExt("allocation 1",
&MyMemSeg,
6u,
4u,
DEF_NULL,
&err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
p_data_2 = (CPU_INT08U *) Mem_SegAllocExt("allocation 2",
&MyMemSeg,
3u,
2u,
DEF_NULL,
&err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
p_data_3 = (CPU_INT08U *) Mem_SegAllocExt("allocation 3",
&MyMemSeg,
8u,
16u,
DEF_NULL,
&err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
}Hardware Memory Segment Allocations#
The Figure - Mem_SegAllocHW() in the Memory Segment Allocations page shows calls to Mem_SegAllocHW(). This flavour of allocation function is a bit different from the first two because it also takes in consideration the padding alignment of the segment from which data is allocated. This padding alignment is specified at segment creation, and it can be set to zero if it is not required. Mem_SegAllocHW() should be used when you are allocating data that will be accessed via DMA, and which are located in cacheable memory. These conditions are often present when using controllers (USB, Ethernet, etc.) in DMA mode. The advantage of Mem_SegAllocHW() is that it makes it easy to ensure that allocated blocks are not within the same cache lines, which makes flush and invalidate operations easier.
In this example, the padding alignment was set to 8 bytes at segment creation.
The first call is made for 5 bytes, but the following 3 are lost, to push the next allocation outside the current 8-byte segment. The second allocation requires a 16-byte alignment, which means that 8 more bytes need to be sacrificed to correctly align this allocation. Then, a bit like for the first allocation, the segment is padded until it reaches an 8-byte boundary, where a future allocation could be made.
Figure - Mem_SegAllocHW()#

Listing - Mem_SegAllocHW() code snippet#
#define MY_MEM_SEG_DATA_SIZE 64u
CPU_INT08U MyMemSegData[MY_MEM_SEG_DATA_SIZE];
MEM_SEG MyMemSeg;
/* ... */
static void MyCreationFnct (void)
{
RTOS_ERR err;
Mem_SegCreate("My mem seg",
&MyMemSeg,
(CPU_ADDR)&MyMemSegData[0u],
MY_MEM_SEG_DATA_SIZE,
8u,
&err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
}
/* ... */
static void MyAlloctionFnct (void)
{
CPU_INT08U *p_data_1;
CPU_INT08U *p_data_2;
RTOS_ERR err;
p_data_1 = (CPU_INT08U *) Mem_SegAllocHW("allocation 1",
&MyMemSeg,
5u,
4u,
DEF_NULL,
&err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
p_data_2 = (CPU_INT08U *) Mem_SegAllocHW("allocation 2",
&MyMemSeg,
12u,
16u,
DEF_NULL,
&err);
if (RTOS_ERR_CODE_GET(err) != RTOS_ERR_NONE) {
/* Handle error. */
}
}