MVP Compiler Configuration#
This page describes *.mlconf keys and merge order. For project setup, see Add Machine Learning to a New or Existing Project. For components, pipeline stages, and troubleshooting, see MVP Compiler.
Default Behavior#
A machine learning application compiles its model through an ml_model instance with a bound project *.mlconf. Set model: to the input .tflite path and regenerate the project. For more information, refer to Model path and project wiring and Add Machine Learning to a New or Existing Project.
With the default *.mlconf shipped for a new ml_model instance, the compiler applies memory planning, graph optimization, and memory optimization. The shipped component template enables graph and memory optimization on top of compiler built-in defaults. Custom memory regions and other advanced options are configurable form *.mlconf file in project.
Register compression always runs and cannot be turned off in *.mlconf. Memory planning uses extension defaults (see memory_planner). Studio supplies the target platform ID from your board or OPN during generation (Supported Platforms).
How Settings Combine#
When you regenerate a project, effective compiler settings are applied in layers. Each higher layer overrides the previous.
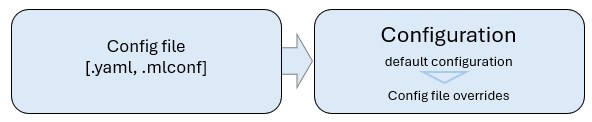
Compiler built-in defaults: Baseline values shipped with the compiler engine.
Component default template:
inst.mlconffrom theml_modelcomponent merges on top of built-in defaults.Your project
*.mlconf: The file you edit underconfig/compiler/, bound to anml_modelinstance in*.slcp(see Model path and project wiring).Project generation: Simplicity Studio supplies the target OPN or board (resolved to a platform ID. For more information, refer to Supported Platforms) when the compiler runs. You normally do not set
platform:in*.mlconf.
Nested sections in *.mlconf merge recursively. Unknown top-level keys are ignored. Regenerate the project after every change to a *.mlconf file so Studio applies the new settings.
Omit a key in your *.mlconf to keep the merged default from lower layers.
Supported Platforms#
SLC passes the target orderable part number (OPN) or board ID from your project configuration. The compiler sanitizes that value and converts it to a canonical platform ID used for the rest of the compile:
If the value already matches a known platform ID (case-insensitive), that ID is used.
Otherwise, the compiler infers a platform from the OPN or board pattern (for example, MG24-style parts →
efr32xg24,brd4187→efr32xg24, Si91x OPNs →siwg917).If no rule matches, the sanitized value is passed through. If the driver does not recognize it, compilation fails.
You do not require to set platform: manually. The conversion happens automatically during generation. Unrecognized targets appear in the build log.
Compiler Platform IDs#
Platform ID | Typical Targets |
|---|---|
| BRD2601 (EFR32) |
| BRD2605 (SiWG917) |
| BRD2608 (EFR32) |
| BRD2719 (EFR32) |
| Generic EFR32 family |
| EFR32xG24 (MG24 / xG24 class parts) |
| EFR32xG26 (MG26 / xG26 class parts) |
| SiMG301 |
| SiWG917 / Si91x SoC |
You can set accelerator: in *.mlconf to override the default for a platform. Typical accelerator IDs: auto (default), cmsis, mvpv1, sw_ref.
Configuration Format#
Project *.mlconf files use YAML with nested sections. The following is a quick overview of all settings with detailed descriptions in Configuration keys. Set model: and include only the sections you want to change.
model: my_model.tflite # input .tflite flatbuffer to compile
output: null # output path; SLC uses autogen
accelerator: auto # kernel backend for target platform
verbose: false # enable verbose compiler logging
log_level: INFO # compiler log level threshold
enable_debugging: false # enable compiler debug behavior
platform: auto # platform ID; SLC supplies target
disabled_layers: [] # layer names excluded from compile
disabled_kernels: [] # kernel names excluded from compile
graph_optimizer:
enabled: true # enable graph optimization stage
remove_constant_layers: true # remove constant-only subgraphs
memory_optimizer:
enabled: true # enable memory optimization stage
weights_paging: single # weights paging mode
buffer_reuse: false # reuse activation buffers when safe
debugging_forced_buffer_sizes: null # debug buffer size overrides
memory_planner:
enabled: true # automatic tensor memory planning
strategy: greedy # placement strategy for tensors
plan_activations: false # include activations in planning
plan_persistent_data: null # plan persistent data placement
memory_specification:
- type: PagingBuffer # memory region type name
size: 32768 # region size in bytes
section: ".bss" # linker section for region
- type: WeightsAndBiases2 # second weights and biases region
size: 0 # zero removes region from layout
codegen:
enabled: true # enable firmware code generation
shorten_paths: true # shorten paths in generated code
output_format: source # header, source, or both
include_paths: [] # extra include paths for codegen
linker_sections: {} # memory type to linker section map
strip_strings: true # strip strings from model output
generate_op_resolver: true # emit model-specific op resolver
prefix: model-stem # symbol prefix; uses .tflite stem
logger_enabled: false # logger hooks in generated code
model_header:
filename: "{prefix}_generated.hpp" # generated model header filename
runtime_memory_size: null # primary tensor arena size bytes
model_memory_section: null # linker section for model memory
add_header_includes: true # add standard includes to header
generate_model_load_function: true # emit model load helper function
generate_op_resolver_instance: true # emit op resolver in header
model_parameters_header:
enabled: false # emit parameters header file
prefix: "SL_TFLITE_MODEL_{prefix}_" # macro prefix for parameters
filename: "{prefix}_generated_parameters.h"When codegen.prefix is model-stem (the default), it is replaced by the .tflite basename and sanitized for C identifiers. {prefix} in generated filenames and macro templates expands accordingly (for example, SL_TFLITE_MODEL_{prefix}_ in model_parameters_header).
The template above describes every supported key. The ml_model component ships inst.mlconf with model: null until you set the .tflite path in your project *.mlconf—see Default behavior.
Configuration Keys#
This section describes all supported configuration keys. Keys with nested sections are annotated with angled brackets where helpful (for example, codegen.model_header).
Many enabled fields accept true, false, or "auto" (the stage runs only when the selected accelerator supports it).
model#
Type:
stringornullDefault:
nullin the component template; required in project configuration filesDescription: Path to the input
.tfliteflatbuffer. Set a full host path to compile a flatbuffer outside the project, or register the file in*.slcpand use the filename (for example,my_model.tflite). See Model path and project wiring.
output#
Type:
stringornullDefault:
nullDescription: Compiler output directory. No need to pass from
.mlconf, SLC uses the autogen path.
platform#
Type:
stringDefault:
autoDescription: Compiler platform ID (see Supported Platforms). Normally supplied by SLC from the target OPN or board.
accelerator#
Type:
stringDefault:
autoDescription: Kernel backend for the target. Typical values:
auto,cmsis,mvpv1,sw_ref, or other IDs supported for the platform.
verbose#
Type:
booleanDefault:
falseDescription: Enables verbose compiler logging.
log_level#
Type:
stringorintegerDefault:
INFODescription:
DEBUG,INFO,WARNING,ERROR,CRITICAL, or a numeric logging level.
enable_debugging#
Type:
booleanDefault:
falseDescription: Enables compiler debug behavior.
disabled_layers#
Type:
listofstringsDefault:
[]Description: Layer names to exclude from compilation.
disabled_kernels#
Type:
listofstringsDefault:
[]Description: Kernel names to exclude from compilation.
graph_optimizer#
Type:
mappingDefault: see Configuration format
Parameter | Type | Default | Description |
|---|---|---|---|
|
|
| Enable/disable the graph optimizer stage. |
|
|
| Remove constant-only subgraphs when the stage runs. |
memory_planner#
Type:
mappingDefault: see Configuration format
Silicon Labs recommends leaving memory_planner.enabled at true for production firmware. Setting it to false disables automatic tensor placement. You must then provide a valid codegen.model_header.runtime_memory_size for your model and target.
To change region sizes or linker sections without disabling the planner, use the memory_specification section.
Parameter | Type | Default | Description |
|---|---|---|---|
|
|
| Enable/disable memory planning. Not recommended to set |
|
|
| Placement strategy (for example, |
|
|
| Plan activation tensors. |
|
|
| Plan persistent data placement. |
memory_optimizer#
Type:
mappingDefault: see Configuration format
Parameter | Type | Default | Description |
|---|---|---|---|
|
|
| Enable/disable the memory optimizer stage. |
|
|
| One of |
|
|
| Enable activation and buffer reuse when safe. |
|
|
| Debug overrides for buffer sizes (kernel name → size). |
memory_specification#
memory_specification is a top-level section in *.mlconf, separate from memory_planner. Memory planning consumes these region definitions when building the allocation plan.
Type:
listornullDefault: platform-dependent regions Configuration format
Description: List of memory region overrides merged with platform defaults. Use
size: 0to remove a region.
Each list entry is a mapping with the following keys:
Parameter | Type | Default | Description |
|---|---|---|---|
|
| — | Required. One of:
|
|
| — | Region size in bytes. |
|
| — | Linker section (for example, |
|
| — | Optional bank geometry. |
Example:
memory_specification:
- type: PagingBuffer
size: 32768
section: ".bss"
- type: WeightsAndBiases2
size: 0codegen#
Type:
mappingDefault: see Configuration format
Parameter | Type | Default | Description |
|---|---|---|---|
|
|
| Enable/disable the code generation stage. |
|
|
| Shorten paths in generated code. |
|
|
| One of |
|
|
| Extra include paths for generated code. |
|
|
| Memory type name → linker section string. Same type names as |
|
|
| Strip strings from the model in output artifacts. |
|
|
| Generate a model-specific op resolver. |
|
|
| Symbol and file prefix. Default expands to the sanitized |
|
|
| Enable logger hooks in generated code. |
|
| — | See codegen.model_header. |
|
| — |
codegen.model_header#
Parameter | Type | Default | Description |
|---|---|---|---|
|
|
| Generated model header filename. |
|
|
| Primary tensor arena size in bytes. Set only when you have a validated size from profiling or documentation—not to replace the memory planner in normal builds. |
|
|
| Linker section for model memory. |
|
|
| Add standard includes to the header. |
|
|
| Emit model load helper function. |
|
|
| Emit op resolver instance in the header. |
codegen.model_parameters_header#
Parameter | Type | Default | Description |
|---|---|---|---|
|
|
| Enable/disable emission of |
|
|
| Macro prefix for parameters. |
|
|
| Output filename. |
Model Path and Project Wiring#
The model key identifies which .tflite flatbuffer an ml_model instance compiles. You can point at a flatbuffer outside the project or include it in the project source tree.
Full host path — Set model: to an absolute path (for example, C:/models/my_model.tflite). The flatbuffer does not need to be listed in *.slcp.
Filename in tflite/ — To make the flatbuffer part of the project, register it in config_file: with directory: tflite, then set model: to the filename (for example, my_model.tflite). During generation, SLC stages the flatbuffer beside the *.mlconf under the virtual tflite/ directory.
Relative path — Resolved relative to the directory that contains the *.mlconf in the generated project tree (for example, ../tflite/my_model.tflite).
Wiring ml_model in *.slcp#
The following registers one model. For multiple models, see Multi-Model Support.
Register and override the component's config slots:
# my_project.slcp (excerpt)
component:
- id: ml_model
instance:
- my_model
config_file:
- path: config/compiler/my_model.mlconf
directory: tflite
override:
component: ml_model
file_id: ml_compiler_config
instance: my_model
- path: config/tflite/my_model.tflite
directory: tfliteThe directory: tflite entries expose both files under the virtual tflite/ tree used during generation. The override: block binds the project *.mlconf to the ml_model instance's ml_compiler_config slot. The .tflite entry is optional when model: uses a full host path; register it in config_file: with directory: tflite when you want the flatbuffer in the project (no override required for the flatbuffer unless your template specifies one).
Align the instance name and *.mlconf basename for clarity (for example, instance my_model → my_model.mlconf). Compiled output filenames use the .tflite filename stem from model:, regardless of the instance name.
If you change which flatbuffer a configuration file applies to, update model: and the matching config_file: .tflite registration, then regenerate the project. Output filenames change with the new flatbuffer stem.
Minimal Project Configuration#
See Model path and project wiring for *.slcp registration. The shipped component template already enables graph and memory optimization.
model: my_model.tflite
graph_optimizer:
enabled: true
memory_optimizer:
enabled: trueSee Also#
Add Machine Learning to a New or Existing Project for *.slcp and *.mlconf setup steps.
MVP Compiler for integration overview and troubleshooting.